
Kubernetes is on fire. Last week VMware® released the State of Kubernetes 2020 report which surveyed companies with 1,000 employees and above. Results were not surprising as the adoptions of this nascent technology are booming. But persistent storage remained the nagging concern for the Kubernetes serving the infrastructure resources to applications instances running in the containers of a pod in a cluster.
The standardization of storage resources have settled with CSI (Container Storage Interface). Storage vendors have almost, kind of, sort of agreed that the API objects such as PersistentVolumes, PersistentVolumeClaims, StorageClasses, along with the parameters would be the way to request the storage resources from the Pre-provisioned Volumes via the CSI driver plug-in. There are already more than 50 vendor specific CSI drivers in Github.
Kubernetes and the CSI (Container Storage Interface) logos
The CSI plug-in method is the only way for Kubernetes to scale and keep its dynamic, loadable storage resource integration with external 3rd party vendors, all clamouring to grab a piece of this burgeoning demands both in the cloud and in the enterprise.
That Nagging Feeling
I have written about Kubernetes and CSI in the past. All for exploratory reasons as I am trying to learn as much as I can to become a practitioner. Here are 2 of my blogs I have written:
- My dilemma of stateful storage marriage in 2018
- Figuring out storage for Kubernetes and Containers in 2019
Since I begun my investigative journey (I called it “down the rabbit hole“), there were many nagging thoughts around the persistent storage and its integration with Kubernetes pods. I was beginning to realize that it was not the persistent storage that made things difficult and clunky. It has always felt “uneven” when the ephemeral philosophy of containers and its respective instances are mushed into a world of persistency and consistency of enterprise applications.
States and Soft States, ACID, BASE and CAP
This “uneven” fit of CSI and the persistent storage paraded by the vendors is really the conflict of the STATE of the container instances in the pod(s). The declarative statements from a YAML (YAML Ain’t Markup Language) API calls would define the PVC claim to the storage resource. An YAML example is shown below are the methods and properties for the Oracle® OCI Volume Provisioner:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysqlclaim
spec:
storageClassName: "oci"
selector:
matchLabels:
failure-domain.beta.kubernetes.io/zone: "US-ASHBURN-AD-1"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi

ACID in Relational DB vs BASE in NoSQL
The reason in my opinion for persistent storage is really to preserve the ACID state as most enterprise applications adopt to. Then there is BASE framework, which dictated the nature of applications and workloads more loosely as cloud-like services came into being. The distribution of data storage across geography brought about the CAP Theorem, and the 3 different states of Consistent, Availability and Partition Tolerance dictate the data store’s decision should one of the 3 states become unavailable.
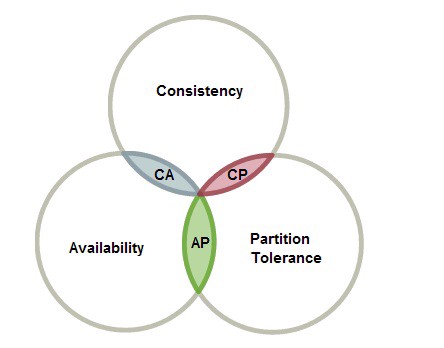
CAP Theorem – Consistency, Availability, Partition Tolerance
Eventually, in order to ensure data consistency and cloud services integrity, all 3 frameworks – ACID, BASE, CAP – will have to come to terms with the growing requirements to ensure storage remain persistent (not just within a Kubernetes pod) beyond what it is now.
When Multi Clouds come around
It will be a few years before the true manifestation of multi clouds. Until then, the true potential of dispensing and expensing the use of multi clouds will be unfulfilled. The ability to optimize and maximize the distribution of computing and application services with stateful and persistent storage resources that go with it, programatically and dynamically adjusting to the applications and workloads changing states should be the utopia we seek.
Then we do not have to bother about the underlying knobs and tweaks of storage or making declarative calls but to say, “I want to scale my enterprise application across the planet, where in EU countries, I want the usage of the data in the applications instance to comply to GDPR. When the enterprise application is used in a country with geo-political issues, I want the workloads to continuously replicate its state to another country, where I can spin up the workload instance services when something happens“. At that point, AIOps and automation would dictate dynamically and naturally the dispensing and expensing of storage resources, persistently and consistently to Kubernetes layer, brokering and orchestrating to the requests of the workloads and the applications it serves.
At this moment, there is still a sizeable gap between the storage technology infrastructure readying itself for the demands orchestrated by the Kubernetes layer, and through its CSI framework. The confinement of the persistent state of storage and the data in it, is imprisoned by the inability to distribute persistence across the cloud data centers, not in the way object storage can.
So far, with my shallow knowledge, Google Cloud Spanner offers a glimpse of the future to distributing persistent and consistent state across the world.

Google Cloud Spanner
Another is the Elastifile Cloud File System, which was acquired by Google last year. Amazon Web Services, through it Elastic File System is also gaining prominence in persistent storage space.
New beginning
The development of maturing Kubernetes not just as a resource orchestrator and broker is going to be even more compelling. The makings of CSI (Container Storage Interface) as the de facto, is just one of the many developments of Kubernetes. Sidecars, is another interesting development in handling the running services of instances in the Kubernetes pod.
We are also seeing the birth of Kubernetes platforms as well as Kubernetes-as-a-Service, aiming to consolidate and simplify the Kubernetes nascent rise in the enterprise applications scene.
This is not a blog to chastise Kubernetes and CSI. The growing demands for cloud native applications (CNA) will at some point, put a divide between the inability of CSI-backed persistent storage to be distributed in a true multi cloud way, and using another persistent storage which can be distributed in a more natural way. In this case, I think object storage or a distributed file system (no, not the Microsoft DFS) is a better, and more natural fit for CNAs, but the enterprise applications are still at an early stage to work with object storage or a distributed file system in its present form.
At some point, the demands of scalability and elasticity will evolve persistent storage beyond the CSI framework, and hopefully takes the storage vendors on a road trip to stretch persistent storage across the data centers in the planet. Things will continue to adapt and change, and that spells an exciting new beginning for persistent storage in Kubernetes.
