
A conversation with a storage executive last week brought up Gluster, a clustered file system I have not explored in many years. I had one interaction months before its acquisition by RedHat® in 2011.
I remembered the Gluster demo at Jaring over a video call, because I was the lead consultant pitching the scale-out NAS solution. It did not go well, and there were “bugs” which made the Head of IT flinched in her seat. Despite Jaring being Malaysia’s technology trailblazer, the impression of Gluster was forgettable. I stayed on the GlusterFS architecture a little while and then it dropped off my radar.
Gluster Scale Out NAS
But after the conversation last week, I am elated to revive my interest in Gluster, knowing that something big and impressive in coming into the fore very soon. Studying the architecture (again!), there are 2 parts of Gluster which excite me. One is the Brick and the other is the lack of a Metadata service.
Building with Bricks
For the uninformed, Gluster is an open source clustered scale-out storage platform. It was acquired by RedHat® late 2011 and is now known as RedHat® Gluster Storage.
The building blocks of Gluster are the Bricks, which are exported directories served from the storage servers (called Nodes) and consolidated as a Volume. A volume, therefore, is an aggregate of several Bricks (and can be dependent on the distributed, replicated and striped factors prescribed), as shown in the diagram below:
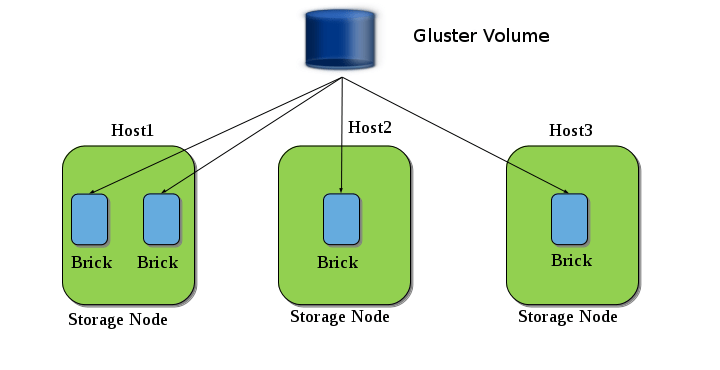
Gluster Bricks aggregated into a Volume
Each of the Storage Nodes are clustered into a Trusted Storage Pool, in which its storage construct is a Volume. From each of the storage node, the glusterfsd daemon runs to export the directory or directories to the Volume.
The distinction of an exported directory as a Brick is important because any supported storage construct (notably a directory) can be a Brick. It can be an md RAIDed “drive” (I did not use the term volume to avoid confusion with Gluster) formatted as an XFS mounted directory or a ZFS file system presented as a mount point.
It is this flexible virtualization of the Brick which gives me the buzz because scale-out solutions can be constructed and crafted easily. More updates in a future blog.
Where did the Metadata Server go?
Early on, many clustered parallel file systems have a metadata service. Even in modern day clustered file systems designs, many still rely on a metadata service to inform I/O requests where to go to get the blocks of file or files. The metadata service is a map, a guide to keep I/Os buzzing, and updated in lock step with the reads and writes.
I usually simplify my thoughts of clustered parallel file systems into 2 categories:
- Symmetric Metadata Service
- Asymmetric Metadata Service
Racking through some of the old SNIA® notes, I found these 2 helpful diagrams to explain the Metadata Services.

Metadata Services in Clustered Parallel File Systems (SNIA)
In the Symmetric Metadata Services, the Metadata Servers (MDS) highlighted in Green, are in-band with the data services of the cluster. The file locking, file attributes updates mechanisms are part of the storage cluster. The RedHat® Sistina Global File System (GFS) and the IBM® GPFS* (General Parallel File System) would fall into this category.
[ *Note: I need an update for IBM® GPFS. I may be wrong because I never studied the design of GPFS in detail. ]
Highlighted in bright pink, the Asymmetric Metadata Services are out-of-band. The metadata services are not part of the active data paths and are housed in separate nodes in the cluster. pNFS (Parallel NFS) and Quantum® Stornext® would be in this category.
I am not going to debate the pros and cons of both Metadata Services but as the demand for ultra high performance, massive scalability and low latency grows, the Metadata Services have become a bottleneck. In many situations, especially when dealing with billions and billions of small updates to files accesses and updates, can take its toll. The avalanche of small random writes to the metadata servers would required proprietary design approaches to overcome this massive challenge, even more so for software defined storage.
Gluster overcomes this by eliminating the Metadata servers altogether. It uses an Elastic Hashing Algorithm, which is simplified to the laymen as metadata-service-on-the-fly. This is the innovative idea which makes Gluster so unique in clustered parallel system design, and it positions the GlusterFS as a linear performance scaling storage platform. Leveraging the powerful CPUs, it is able to calculate the hash to the addresses of the striped files in microseconds, giving it the low latency and improving throughput. In this day and age, this innovative design is vital to serve demanding workloads.
This is the second part of my excitement.
Yes. It is Glusterific!
Obviously I am combining the words “Gluster” and “Terrific” into Glusterific, just like Gluster was initiated “GNU” and “Cluster” in the same word play.Why am I so amped up about this?
Gluster has been in RedHat® for more than 8 years. It is part of RedHat®’s offering as CRS (Container Ready Storage) and CNS (Container Native Storage) in RedHat® OpenShift. It is part of RedHat® HCI with RHEV. It has overlaps with RedHat® Ceph Storage, but is far superior in terms of performance. IBM® acquired RedHat® in 2019. Soon Gluster has to vie for attention in IBM® stable of storage platforms. Outside this, Sangfor has GlusterFS in its HCI.
The early on Open Source decision has given Gluster the freedom to be independent from the claws of a large corporate behemoth. But in order for Gluster to thrive and stand on its own, it must have growth projects that are worthy of its community, and worthy of its developers.
At the recent RedHat® Summit in April last month, there were a few significant announcements that seem to put Gluster’s prominence into the shadows. RedHat® OpenShift Container Platform and the Container Storage are shifting to Ceph as the storage of choice, and the NooBaa acquisition from 2018 is also making its presence felt too. You can read about the developments and high level roadmaps here.
What does this spell for Gluster? Although I am confident that RedHat® will continue to push for the growth and longevity of Gluster, only time will tell how IBM® corporate culture will work into RedHat®. Ceph seems to getting a bigger share of the attention as well, ahead of Gluster.
Therefore, larger commercial success of 3rd party vendors developing and using Gluster is crucial for its own survival, with or without RedHat® and IBM®.
Going back to the conversation I had with a storage executive last week, the information shared made truly excited about Gluster’s future. In fact, it’s Glusterific! 🙂
