[ Preamble: This analysis focuses on my own journey as I incorporate my past experiences into this new market segment called AI Data Infrastructure, and gaining new ones.
There are many elements of HPC (High Performance Computing) at play here. Even though things such as speeds and feeds, features and functions crowd many conversations, as many enterprise storage vendors like to do, these conversations, in my opinion, are secondary. There are more vital and important operational technology and technical elements that an organization has to consider prudently, vis-a-vis to ROIs (returns of investments). They involve asking the hard questions beyond the marketing hype and fluff. I call these elements of consideration Storage Objectives and Key Results (OKRs) for AI Data Infrastructure.
I had to break this blog into 2 parts. It has become TL;DR-ish. This is Part 1 ]
I have just passed my 6-month anniversary with DDN. Coming into the High Performance Storage System (HPSS) market segment, with the strong focus on the distributed parallel filesystem of Lustre®, there was a high learning curve for me. I spend over 3 decades in Enterprise Storage, with some of the highest level of storage technologies there were in that market segment. And I have already developed my own approach to enterprise storage, based on the A.P.P.A.R.M.S.C.. That was already developed and honed from 25 years ago.
The rapid adoption of AI has created a technology paradigm shift. Artificial Intelligence (AI) came in and blurred many lines. It also has been evolving my thinking when it comes to storage for AI. There is also a paradigm shift in my thoughts, opinions and experiences as well.
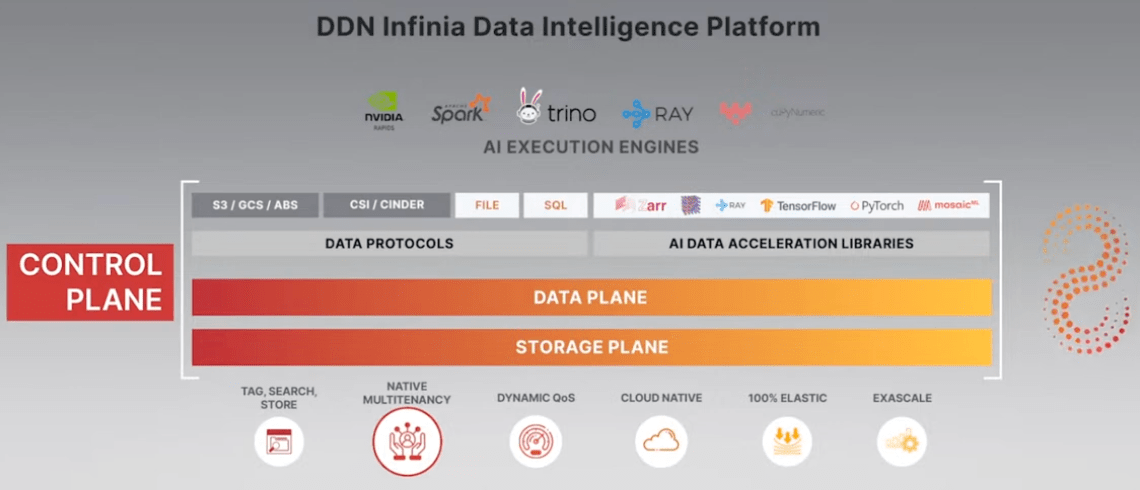
AI has brought HPSS technologies like Lustre® in DDN EXAscaler platform , proven in the Supercomputing world, to a new realm – the AI Data Infrastructure market segment. On the other side, many enterprise storage vendors aspire to be a supplier to the AI Data Infrastructure opportunities as well. This convergence from the top storage performers for Supercomputing, in the likes of DDN, IBM® (through Storage Scale), HPE® (through Cray, which by-the-way often uses the open-source Lustre® edition in its storage portfolio), from the software-defined storage players in Weka IO, Vast Data, MinIO, and from the enterprise storage array vendors such as NetApp®, Pure Storage®, and Dell®.
[ Note that I take care not to name every storage vendor for AI because many either do OEMs or repacking and rebranding of SDS technology into their gear such as HPE® GreenLake for Files and Hitachi® IQ. You can Google to find out who the original vendors are for each respectively. There are others as well. ]
In these 3 simplified categories (HPSS, SDS, Enterprise Storage Array), I have begun to see a pattern of each calling its technology as an “AI Data Infrastructure”. At the same time, I am also developing a new set of storage conversations for the AI Data Infrastructure market segment, one that is based on OKRs (Objectives and Key Results) rather than just features, features and more features that many SDS and enterprise storage vendors like to tout. Here are a few thoughts that we should look for when end users are considering a high-speed storage solution for their AI journey.

AI Data Infrastructure
GPU is king
In the AI world, the GPU infrastructure is the deity at the altar. The utilization rate of the GPUs is kept at the highest to get the maximum compute infrastructure return-on-investment (ROI). Keeping the GPUs resolutely busy is a must. HPSS is very much part of that ecosystem.
These are a few OKRs I would consider the storage or data infrastructure for AI.
- Reliability
- Speed
- Power Efficiency
- Security
Let’s look at each one of them from the point of view of a storage practitioner like me.
Continue reading →