
[Preamble: I have been invited by GestaltIT as a delegate to their Tech Field Day for Storage Field Day 18 from Feb 27-Mar 1, 2019 in the Silicon Valley USA. My expenses, travel and accommodation were covered by GestaltIT, the organizer and I was not obligated to blog or promote their technologies presented at this event. The content of this blog is of my own opinions and views]
I was first introduced to WekaIO back in Storage Field Day 15. I did not blog about them back then, but I have followed their progress quite attentively throughout 2018. 2 Storage Field Days and a year later, they were back for Storage Field Day 18 with a new CTO, Andy Watson, and several performance benchmark records.
Blowout year
2018 was a blowout year for WekaIO. They have experienced over 400% growth, placed #1 in the Virtual Institute IO-500 10-node performance challenge, and also became #1 in the SPEC SFS 2014 performance and latency benchmark. (Note: This record was broken by NetApp a few days later but at a higher cost per client)
The Virtual Institute for I/O IO-500 10-node performance challenge was particularly interesting, because it pitted WekaIO against Oak Ridge National Lab (ORNL) Summit supercomputer, and WekaIO won. Details of the challenge were listed in Blocks and Files and WekaIO Matrix Filesystem became the fastest parallel file system in the world to date.
Control, control and control
I studied WekaIO’s architecture prior to this Field Day. And I spent quite a bit of time digesting and understanding their data paths, I/O paths and control paths, in particular, the diagram below:
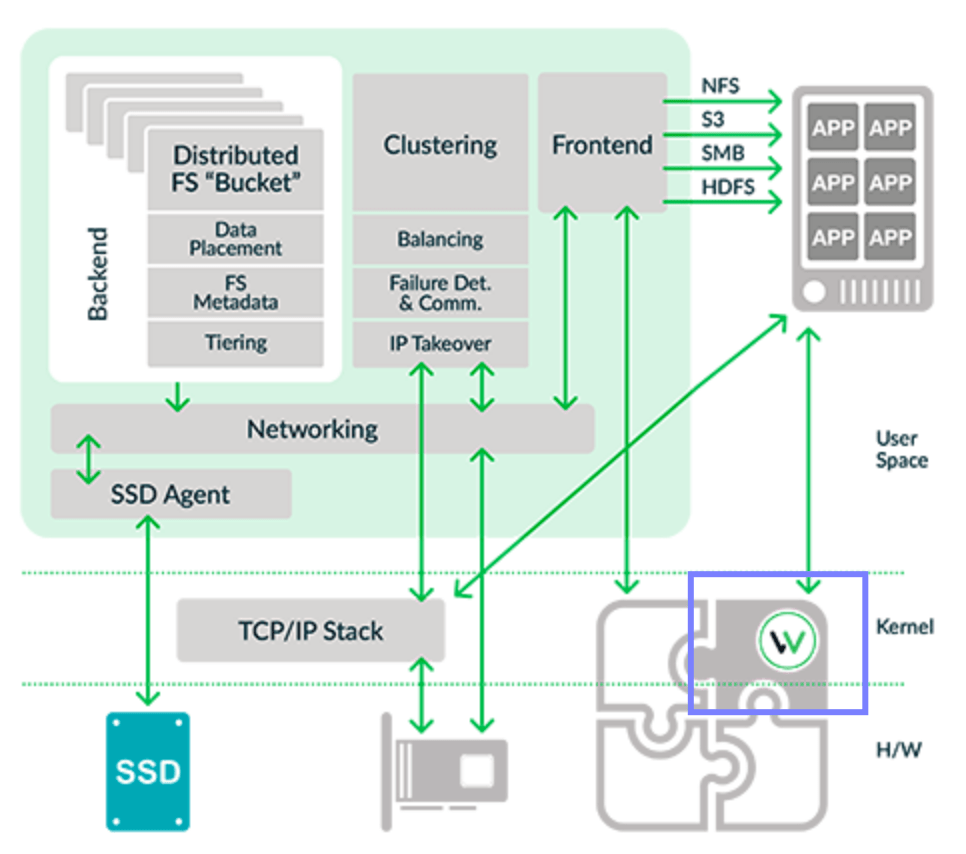 Starting from the top right corner of the diagram, applications on the Linux client (running Weka Client software) and it presents to the Linux client as a POSIX-compliant file system. Through the network, the Linux client interacts with the WekaIO kernel-based VFS (virtual file system) driver which coordinates the Front End (grey box in upper right corner) to the Linux client. Other client-based protocols such as NFS, SMB, S3 and HDFS are also supported. The Front End then interacts with the NIC (which can be 10/100G Ethernet, Infiniband, and NVMeoF) through SR-IOV (single root IO virtualization), bypassing the Linux kernel for maximum throughput. This is with WekaIO’s own networking stack in user space.
Starting from the top right corner of the diagram, applications on the Linux client (running Weka Client software) and it presents to the Linux client as a POSIX-compliant file system. Through the network, the Linux client interacts with the WekaIO kernel-based VFS (virtual file system) driver which coordinates the Front End (grey box in upper right corner) to the Linux client. Other client-based protocols such as NFS, SMB, S3 and HDFS are also supported. The Front End then interacts with the NIC (which can be 10/100G Ethernet, Infiniband, and NVMeoF) through SR-IOV (single root IO virtualization), bypassing the Linux kernel for maximum throughput. This is with WekaIO’s own networking stack in user space.
On the top left corner box is the Back End (BE), which comprises of multiple logical entities. The logical BE entities manages the file system metadata, the tiering and the protection and it can be moved and distributed to other WekaIO server nodes for maximum scaling. The BE is also responsible for fully managing the NVMe/SSD drives of the server node as part of its I/O stack.
The middle box is the Clustering, and handles the cluster management, load balancing and HA failover functionalities.
From that understanding, WekaIO I/O subsystem is basically another “operating system” running within the Linux operating system. It manages its own scheduling, I/O and networking stack and memory management, with the Linux kernel knowing the resources used or being used, but not interfering with what WekaIO is doing. All these, with exception of the VFS driver mentioned earlier, are in Linux User space, further empowering scalability and performance.
It is this complete control of the I/O subsystem and the NVMe devices and drivers that give WekaIO its high performance and wide scalability, and its ultra low latency and high throughput for demanding application workloads.
4K please
Another very interesting thing about WekaIO Matrix file system is that they use 4K blocks. This goes against the grain for most parallel file systems I know because in most HPC shops, the block sizes used are usually much larger – 256K, 1MB. The NVMe and NVMeoF can support upto 64,000 commands in/out of 64,000 queues and WekaIO 4K block implementation fits well into the term “Parallelize Everything“. And WekaIO also does not care about where the data reside because the data is distributed across the server nodes of the cluster. The Data Locality, as it was quoted, is irrelevant because NVMe and NVMe over the WekaIO own distributed network algorithm remove the burden of keeping track of the data at all times.
That is why WekaIO has come out to claim that their shared storage performance is faster than local drives.
This 4K/Parallelize Everything/NVMe combo gives WekaIO a huge performance leg up over legacy HPC file systems such as Lustre and IBM GPFS because its Matrix file system is designed for the NVMe era.
An even greater 2019
I blogged about HPC storage being sexy some months back. Fueled by the new generation of AI/DL application workloads, commercial HPC is reinventing a brand new market segment between enterprise storage and super computing storage.
The mix of small size IO driven metadata, and trillions of data objects, and high throughput data streams have exposed the weaknesses of HPC parallel file systems like Lustre and GPFS. And most of these legacy file systems were designed in the spinning disks era and would require a complete architecture redesign for the NVMe era. WekaIO is certainly well positioned for the NVMe era and beyond.
I see WekaIO ready for leaps and bounds in 2019. And last week, I very much wanted to meet them at SC Asia 2019 in Singapore. I was disappointed because I was admitted to the hospital for health issues. But I hope to see them soon, especially with my friend, Andy Watson, as their CTO driving them forward.

Pingback: Storage Field Day 18 – Wrap-up and Link-o-rama | PenguinPunk.net
Pingback: Save money with a fast WekaIO file system - FastStorage
Pingback: WekaIO Controls Their Performance Destiny - Tech Field Day