New generations of applications and workloads like AI/DL (Artificial Intelligence/Deep Learning), and HPC (High Performance Computing) are breaking the seams of entrenched storage infrastructure models and frameworks. We cannot continue to scale-up or scale-out the storage infrastructure to meet these inundating fluctuating I/O demands. It is time to look at another storage architecture type of infrastructure technology – Composable Infrastructure Architecture.
Infrastructure is changing. The previous staid infrastructure architecture parts of compute, network and storage have long been thrown of the window, precipitated by the rise of x86 server virtualization almost 20 years now. It triggered a tsunami of virtualizing everything, including storage virtualization, which eventually found a more current nomenclature – Software Defined Storage. Both storage virtualization and software defined storage (SDS) are similar and yet different and should be revered through different contexts and similar goals. This Tech Target article laid out both nicely.
As virtualization raged on, converged infrastructure (CI) which evolved into hyperconverged infrastructure (HCI) went fever pitch for a while. Companies like Maxta, Pivot3, Atlantis, are pretty much gone, with HPE® Simplivity and Cisco® Hyperflex occasionally blipped in my radar. In a market that matured very fast, HCI is now dominated by Nutanix™ and VMware®, with smaller Microsoft®, Dell EMC® following them.
From HCI, the attention of virtualization has shifted something more granular, more scalable in containerization. Despite a degree of complexity, containerization is taking agility and scalability to the next level. Kubernetes, Dockers are now mainstay nomenclature of infrastructure engineers and DevOps. So what is driving composable infrastructure? Have we reached the end of virtualization? Not really.

Evolution of infrastructure. Source: IDC
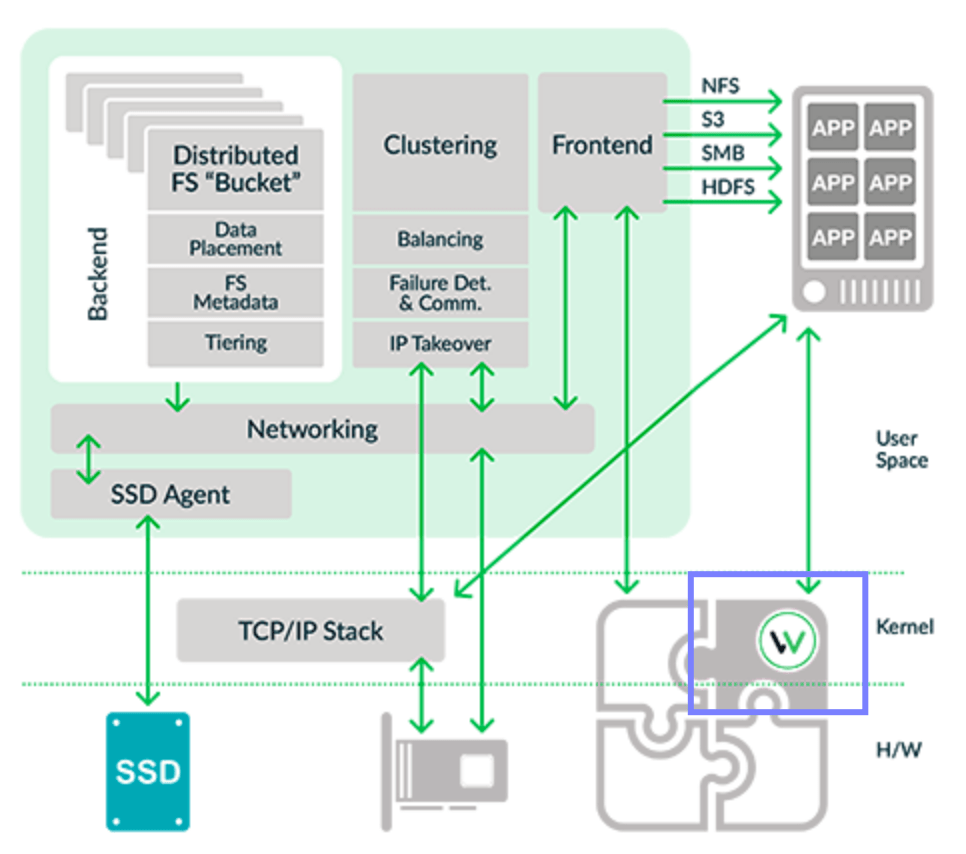
It is just that one part of the infrastructure landscape is changing. This new generation of AI/ML workloads are flipping the coin to the other side of virtualization. As we see the diagram above, IDC brought this mindset change to get us to Think Composability, the next phase of Infrastructure.