I have been reading a couple of articles over the weekend which started by placing the weights of outdated networking infrastructure slowing down AI ambitions. The 2 articles are:
I did not fully agree that networking infrastructure is the main inhibitor of AI ambitions per se. Not from the experiences and the present development in high performance networking of what I know so far. In fact, AI networking infrastructure has been growing leaps and bounds, laying down ultra-high throughput plumbing between the GPUs (inadvertently up the stack to the AI models and applications) and the data storage infrastructure.
In fact, in one of DDN’s NCP customers, I have seen a 10-node DDNEXAscaler cluster deliver almost 1.1TB/sec read and 750GB/sec write throughput to the GPU compute cluster, out-of-the-box, all with 200Gbps networking gear.
The IT industry uses the word “platform” all the time. Often, I find myself shifting between the many jargons circling “platform”, loosely. I am pretty sure many others are doing so as well.
I finally found the word “platformization” giving right vibes in a meaningful way in February last year, when Palo Alto Networkspivoted to platformization. Their stock tumbled that day. Despite the ambiguous definition “platformization” when Palo Alto Networks (PANW) mentioned it, I understood their strategy.
Defence-in-Depth in cybersecurity wasn’t exactly working for many organizations. Cybersecurity point solutions peppered the landscape. There were so many leaks and gaps. Platformization, from the PANW‘s point-of-view, is the reverse C&C (command & control), if you know the cybersecurity speak. PANW wants to take charge all the way for all things cybersecurity, and it made sense to me from a data perspective.
Paradigm shift for Data.
For the longest time, networked storage technology has been about data sharing, be it blocks, files or objects. The data from these protocols is delivered over the network, mostly over Fibre Channel and/or Ethernet (although I remembered implementing NFS over Asynchronous Transfer Mode at Sarawak Shell in East Malaysia), in a client-server fashion.
By late 2000s onwards, unified storage or multi-protocol storage (where the storage array is able to served all 3 SAN, NAS and S3 services) was all the rage. All the prominent enterprise storage vendors had a solution or two in their solutions portfolio. I started viewing networked storage as a Data Services Platform which I started explaining it in 2017. Within the data services platform, various features revolve around my A.P.P.A.R.M.S.C. framework (I crafted the initial framework in 2000, thanks to Jon Toigo‘s book – The Holy Grail of Data Management). This framework and the approach I used for my consulting and analyst work worked well and is still relevant, even after 25 years.
But AI is changing the data landscape. AI is changing the way data is consumed and processed through the networks between the compute layer and the storage layer. It is indeed, for me, a paradigm shift of data, and the storage layer, better known as AI Data Infrastructure now, is shifting as well. And this shift will accelerate the exponential growth in innovations, with AI and super-charged data leading the way.
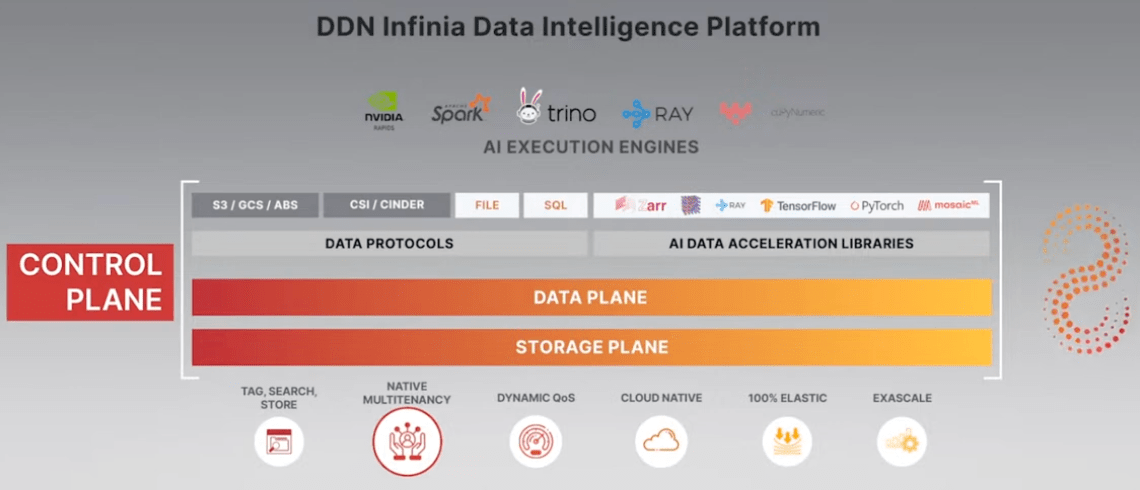
DDN Infinia Data Intelligence Platform (screencapture from DDN Beyond Artificial webinar)
[ Preamble: This analysis focuses on my own journey as I incorporate my experiences into this new market segment called AI Data Infrastructure. There are many elements of HPC (High Performance Computing) at play here. Even though things such as speeds and feeds, features and functions crowd many conversations, as many enterprise storage vendors do, these conversations, in my opinion, are secondary. There are more vital and important operational technology and technical elements that an organization has to consider prudently. They involve asking the hard questions beyond the marketing hype and fluff. I call these elements of consideration Storage Objectives and Key Results (OKRs) for AI Data Infrastructure.
I had to break this blog into 2 parts. It has become TL;DR-ish. This is Part 2 ]
This is a continuation from Part 1 of my blog last week. I spoke about the 4 key OKRs (Objectives and Key Results) we look at from the storage point-of-view with regards to AI data infrastructure. To recap, they are:
When you operate a GPU compute farm, whether it is 8 GPUs or 16,384 GPUs, keep operations tight is vital to ensure that maximum power efficiency is right up there with the rest of the operational OKRs. The element of power consumption becomes a cost factor in the data infrastructure design for AI.
2 very important units of measurements I would look into, and that have become valuable OKRs to achieve are Performance per Watt (Performance/Watt) and Performance per Rack Unit (Performance/RU).
[ Preamble: This analysis focuses on my own journey as I incorporate my past experiences into this new market segment called AI Data Infrastructure, and gaining new ones.
There are many elements of HPC (High Performance Computing) at play here. Even though things such as speeds and feeds, features and functions crowd many conversations, as many enterprise storage vendors like to do, these conversations, in my opinion, are secondary. There are more vital and important operational technology and technical elements that an organization has to consider prudently, vis-a-vis to ROIs (returns of investments). They involve asking the hard questions beyond the marketing hype and fluff. I call these elements of consideration Storage Objectives and Key Results (OKRs) for AI Data Infrastructure.
I had to break this blog into 2 parts. It has become TL;DR-ish. This is Part 1 ]
I have just passed my 6-month anniversary with DDN. Coming into the High Performance Storage System (HPSS) market segment, with the strong focus on the distributed parallel filesystem of Lustre®, there was a high learning curve for me. I spend over 3 decades in Enterprise Storage, with some of the highest level of storage technologies there were in that market segment. And I have already developed my own approach to enterprise storage, based on the A.P.P.A.R.M.S.C.. That was already developed and honed from 25 years ago.
The rapid adoption of AI has created a technology paradigm shift. Artificial Intelligence (AI) came in and blurred many lines. It also has been evolving my thinking when it comes to storage for AI. There is also a paradigm shift in my thoughts, opinions and experiences as well.
AI has brought HPSS technologies like Lustre® in DDN EXAscaler platform , proven in the Supercomputing world, to a new realm – the AI Data Infrastructure market segment. On the other side, many enterprise storage vendors aspire to be a supplier to the AI Data Infrastructure opportunities as well. This convergence from the top storage performers for Supercomputing, in the likes of DDN, IBM® (through Storage Scale), HPE® (through Cray, which by-the-way often uses the open-source Lustre® edition in its storage portfolio), from the software-defined storage players in Weka IO, Vast Data, MinIO, and from the enterprise storage array vendors such as NetApp®, Pure Storage®, and Dell®.
[ Note that I take care not to name every storage vendor for AI because many either do OEMs or repacking and rebranding of SDS technology into their gear such as HPE® GreenLake for Files and Hitachi® IQ. You can Google to find out who the original vendors are for each respectively. There are others as well. ]
In these 3 simplified categories (HPSS, SDS, Enterprise Storage Array), I have begun to see a pattern of each calling its technology as an “AI Data Infrastructure”. At the same time, I am also developing a new set of storage conversations for the AI Data Infrastructure market segment, one that is based on OKRs (Objectives and Key Results) rather than just features, features and more features that many SDS and enterprise storage vendors like to tout. Here are a few thoughts that we should look for when end users are considering a high-speed storage solution for their AI journey.
AI Data Infrastructure
GPU is king
In the AI world, the GPU infrastructure is the deity at the altar. The utilization rate of the GPUs is kept at the highest to get the maximum compute infrastructure return-on-investment (ROI). Keeping the GPUs resolutely busy is a must. HPSS is very much part of that ecosystem.
These are a few OKRs I would consider the storage or data infrastructure for AI.
Reliability
Speed
Power Efficiency
Security
Let’s look at each one of them from the point of view of a storage practitioner like me.
When I first heard of the word “AI Factory”, the world was blaring Jensen Huang‘s keynote at NVIDIA GTC24. I thought those were cool words, since he mentioned about the raw material of water going into the factory to produce electricity. The analogy was spot on for the AI we are building.
As I engage with many DDN partners and end users in the region, week in, week out, the “AI Factory” word keeps popping into conversations. Yet, many still do not know how to go about building this “AI Factory”. They only know they need to buy GPUs, lots of them. These companies’ AI ambitions are unabated. And IDC predicts that worldwide spending on AI will double by 2028, and yet, the ROI (returns on investment) remains elusive.
At the ground level, based on many conversations so far, the common theme is, the steps to begin building the AI Factory are ambiguous and fuzzy to most. I like to share my views from a data storage point of view. Hence, my take on the Data Factory for AI.
Are you AI-ready?
We have to have a plan but before we take the first step, we must look at where we are standing at the present moment. We know that to train AI, the proverbial step is, we need lots of data. Deep Learning (DL) works with Large Language Models (LLMs), and Generative AI (GenAI), needs tons of data.
If the company knows where they are, they will know which phase is next. So, in the AI Maturity Model (I simplified the diagram below), where is your company now? Are you AI-ready?
Simplified AI Maturity Model
Get the Data Strategy Right
In his interview with CRN, MinIO’s CEO AB Periasamy quoted “For generative AI, they realized that buying more GPUs without a coherent data strategy meant GPUs are going to idle out”. I was struck by his wisdom about having a coherent data strategy because that is absolutely true. This is my starting point. Having the Right Data Strategy.
In the AI world, from a data storage guy, data is the fuel. Data is the raw material that Jensen alluded to, if it was obvious. We have heard this anecdotal quote many times before, even before the AI phenomenon took over. AI is data-driven. Data is vital for the ROI of AI projects. And thus, we must look from the point of the data to make the AI Factory successful.
It has been 2 months into my new role at DDN as a Solutions Architect. With many revolving doors around me, I have been trying to find the essence, the critical cog of the data infrastructure that supports the accelerated computing of the Nvidia GPU clusters. The more I read and engage, a pattern emerged. I found that cog in the supercharged data paths between the storage infrastructure systems and the GPU clusters. I will share more.
To set the context, let me start with a wonderful article I read in CIO.com back in July 2024. It was titled “Storage: The unsung hero of AI deployments“. It was music to my ears because as a long-time practitioner in the storage technology industry, it is time the storage industry gets its credit it deserves.
What is the data path?
To put it simply, a Data Path, from a storage context, is the communication route taken by the data bits between the compute system’s processing and program memory and the storage subsystem. The links and the established sessions can be within the system components such as the PCIe bus or external to the system through the shared networking infrastructure.
High speed accelerated data paths
In the world of accelerated computing such as AI and HPC, there are additional, more advanced technologies to create even faster delivery of the data bits. This is the accelerated data paths between the compute nodes and the storage subsystems. Following on, I share a few of these technologies that are lesser used in the enterprise storage segment.
I am strong believer of using the right tool to do the job right. I have said this before 2 years ago, in my blog “Stating the case for a Storage Appliance approach“. It was written when I was previously working for an open source storage company. And I am an advocate of the crafter versus assembler mindset, especially in the enterprise and high- performance storage technology segments.
I have joined DDN. Even with DDN that same mindset does not change a bit. I have been saying all along that the storage appliance model should always be the mindset for the businesses’ peace-of-mind.
My view of the storage appliance model began almost 25 years. I came into NAS systems world via Sun Microsystems®. Sun was famous for running NFS servers on general Sun Solaris servers. NFS services on Unix systems. Back then, I remember arguing with one of the Sun distributors about the tenets of running NFS over 100Mbit/sec Ethernet on Sun servers. I was drinking Sun’s Kool-Aid big time.
When I joined Network Appliance® (now NetApp®) in 2000, my worldview of putting software on general purpose servers changed. Network Appliance®, had one product family, the FAS700 (720, 740, 760) family. All NetApp® did was to serve NFS services in the beginning. They were the NAS filers and nothing else.
I was completed sold on the appliance way with NetApp®. Firstly, it was my very first time knowing such network storage services could be provisioned with an appliance concept. This was different from Sun. I was used to managing NFS exports on a Sun SPARCstation 20 to Unix clients in the network.
Secondly, my mindset began to shape that “you have to have the right tool to the job correctly and extremely well“. Well, the toaster toasts bread very well and nothing else. And the fridge (an analogy used by Dave Hitz, I think) does what it does very well too. That is what the appliance does. You definitely cannot grill a steak with a bread toaster, just like you can’t run an excellent, ultra-high performance storage services to serve the demanding AI and HPC applications on a general server platform. You have to have a storage appliance solution for High-Speed Storage.
That little Network Appliance® toaster award given out to exemplary employees stood vividly in my mind. The NetApp® tagline back then was “Fast, Simple, Reliable”. That solidifies my mindset for the high-speed storage in AI and HPC projects in present times.
I like to think about what the end users are thinking about. There are investments costs involved, and along with it, risks to the investments as well as their benefits. Let’s just simplify and lump them into Cost-Benefits-Risk analysis triangle. These variables come into play in the decision making of AI and HPC projects.
NAS (network attached storage) is obviously the file-level workhorse for shared resources in the network of any organization.SMB (server message block) for Windows environments and NFS (network file system) for Linux platforms are the 2 most prominent protocols that rule the NAS world. Of course we have SMB implementations in the form of Samba and others in non-Windows, Linux and NFS implementations in Windows as well.
As the versions of both network file sharing protocols iterated, present versions of SMB v3.x and NFS v4.x (NFS v3 on the supported Linux kernel version) on the client-side have evolved well. Both now have enhanced resiliency and performance improvement features. And there is an underlying similarity of both implementations. This blog looks at the client-side architectures of both.
One TCP connection
NAS is a client-server architecture. Over the network, NAS clients (SMB or NFS) access their corresponding NAS server(s) – SMB or NFS server(s) – through the TCP/IP network.
NAS client-server architecture (Credit: https://hypertecsp.com/en-CA/knowledge-base/nas-vs-san/)
One very important key starting point to note is the use of one TCP connection per NAS client to the NAS server relationship. For both SMB and NFS, there is just one TCP link between client and the server even if there are several SMB mapped shares or NFS mount points respectively on the clients.
For a long time, this one TCP connection is sufficient for the NAS traffic. But as the network file accesses grow, this connection becomes both a single point of failure as well as a performance bottleneck.
I am on a learning streak again. The most prominent technology that keeps landing on my tray at present is, of course, Artificial Intelligence (AI).
AI is hot. Very hot. And overhyped. Everyone is an expert nowadays. Yeah, right. Not me.
Underneath that glossy veneer of the AI hype, there are much going on behind the scenes to make AI great. The 2 areas I have been involved in and practiced for a long time are data infrastructure a.k.a. storage, and data management. And both are playing prominent parts in the advancement of the AI ecosystem. This makes me very excited.
I am no expert, but learning from various sources is already telling me that AI is pushing both storage and data management harder than ever before, much harder than traditional enterprise on-premises use cases and even the cloud computing applications. I ask myself, “where do I start my learning again?” as I journal my process.
Storage performance in a Data Pipeline
Speed of how AI responds is Trust. The faster it is to the accurate and relevant responses will build trust in AI. To get to the speed that we want is not an easy thing, and storage a.k.a. data infrastructure is doing its part. I pick up my learning from understanding the AI pipeline. One early help comes from my friend, Gina Rosenthal, who attended the Solidigm‘s presentation at AI Field Day in February 2024. Her article, titled “Why storage matters for AI – Solidigm“, kickstarted my learning juices again.
I was particularly captured by this slide in Gina’s article. It defines the laborious path data takes to become useful for AI applications.
Storage and the 5 stages of AI Work (reference: Solidigm presentation on AI Field Day)
I was listening to several storage luminaries in the GestaltIT’s podcast “No one understands Storage anymore” a few of weeks ago. Around the minute of 11.09 in the podcast, Dr. J. Metz, SNIA® Chair, brought up this is powerful quote “Storage does not mean Capacity“. It struck me, not in a funny way. It is what it is, and it something I wanted to say to many who do not understand the storage solutions they are purchasing. It exemplifies what is wrong in the many organizations today in their understanding of investing in a storage infrastructure project.
This is my pet peeve. The first words uttered in most, if not all storage requirements in my line of work are, “I want this many Terabytes of storage“. There are no other details and context of what the other requirement factors are, such as availability, performance, future growth, etc. Or even the goals to achieve when purchasing a storage system and operating it. What is the improvement they are looking for?What are the problems to solve?
Where is the OKR?
It pains me to say this. For the folks who have in the IT industry for years, both end users and IT purveyors alike, most are absolutely clueless about OKR (Objectives and Key Results) for their storage infrastructure project. Many cannot frame the data challenges they are facing, and they have no idea where to go next. There is no alignment. There is no strategy. Even worse, there is no concept of how their storage infrastructure investments will improve their business and operations.
Just the other day, one company director from a renown IT integrator here in Malaysia came calling. He has been in the IT industry since 1989 (I checked his Linkedin profile), asking to for a 100TB storage quote. I asked a few questions about availability, performance, scalability; the usual questions a regular IT guy would ask. He has no idea, and instead of telling me he didn’t know, he gave me a runaround of this and that. Plenty of yada, yada nonsense.
In the end, I told him to buy a consumer grade storage appliance from Taiwan. I will just let him make a fool of himself in front of his customer since he didn’t want to take accountability of ensuring his customer get a proper enterprise storage solution in good faith. His customer is probably in the same mould as well.
Defensive Strategies as Data Foundations
A strong storage infrastructure foundation is vital for good Data Credibility. If you do the right things for your data, there is Data Value, and it will serve your business well. Both Data Credibility and Data Value create confidence. And Confidence equates Trust.
In order to create the defensive strategies let’s look at storage Availability, Protection, Accessibility, Management Security and Compliance. These are 6 of the 8 data points of the A.P.P.A.R.M.S.C. framework.
Offensive Strategies as Competitive Advantage
Once we have achieved stability of the storage infrastructure foundation, then we can turn over and drive towards storage Performance, Recovery, plus things like Scalability and Agility.
With a strong data infrastructure foundation, the organization can embark on the offensive, and begin their business transformation journey, knowing that their data is well run, protection, and performs.
Alignment with Data and Business Goals
Why are the defensive and offensive strategies requiring alignment to business goals?
The fact is simple. It is about improving the business and operations, and setting OKRs is key to measure the ROI (return of investment) of getting the storage systems and the solutions in place. It is about switching the cost-fearing (negative) mindset to a profit-conviction (positive) mindset.
For example, maybe the availability of the data to the business is poor. Maybe there is the need to have access to the data 24×7, because the business is going online. The simple measurable fact is we can move availability from 95% uptime to 99.99% uptime with an HA storage system.
Perhaps there are concerns about recoverability in the deluge of ransomware threats. Setting new RPO goals from 24 hours to 4 hours is a measurable objective to enhance data resiliency.
Or getting the storage systems to deliver higher performance from 350 IOPS to 5000 IOPS for the database.
What I am saying here is these data points are measurable, and they can serve as checkpoints for business and operational improvements. From a management perspective, these can be used as KPI (key performance index) to define continuous improvement of Data Confidence.
Furthermore, it is easy when a OKR dashboard is used to map the improvement markers when organizations use storage to move from point A to point B, where B equates to a new success milestone. The alignment sets the paths to the business targets.
Storage does not mean only Capacity
The sad part is what the OKRs and the measured goals alignments are glaringly missing in the minds of many organizations purchasing a storage infrastructure and data management solution. The people tasked to source a storage technology solution are not placing a set of goals and objectives. Capacity appears to be the only thing on their mind.
I am about to meet a procurement officer of a customer soon. She asked me this question “Why is your storage so expensive?” over email. I want to change her mindset, just like the many officers and C-levels who hold the purse strings.
Let’s frame the use storage infrastructure in the real world. Nobody buys a storage system just to keep data in there much like a puddle keeps stagnant water. Sooner or later the value of the data in the storage evaporates or the value becomes dull if the data is not used well in any ways, shape or form.
Storage systems and the interconnected pathways from on premises, to the next premises, to the edge and to the clouds serve the greater good for Data. Data is used, shared, shaped, improved, enhanced, protected, moved, and more to deliver Value to the Business.
Storage capacity is just one of the few factors to consider when investing in a storage infrastructure solution. In fact, capacity is probably the least important piece when considering a storage solution to achieve the company’s OKRs. If we think about it deeper, setting the foundation for Data in the defensive manner will help elevate value of the data to be promoted with the offensive strategies to gain the competitive advantage.
Storage infrastructure and storage solutions along with data management platforms may appear to be a cost to the annual budgets. If you know set the OKRs, define A to get to B, alignment the goals, storage infrastructure and the data management platforms and practices are investments that are worth their weight in gold. That is my guarantee.
On the flip side, ignoring and avoiding OKRs, and set the strategies without prudence will yield its comeuppance. Technical debts will prevail.