Seriously? 4 freaking terabyte disk drives?
The enterprise SATA/SAS disks have just grown larger, up to 4TB now. Just a few days ago, Hitachi boasted the shipment of the first 4TB HDD, the 7,200 RPM Ultrastar™ 7K4000 Enterprise-Class Hard Drive.

And just weeks ago, Seagate touted their Heat-Assisted Magnetic Recording (HAMR) technology will bring forth the 6TB hard disk drives in the near future, and 60TB HDDs not far in the horizon. 60TB is a lot of capacity but a big, big nightmare for disks availability and data backup. My NetApp Malaysia friend joked that the RAID reconstruction of 60TB HDDs would probably finish by the time his daughter finishes college, and his daughter is still in primary school!.
But the joke reflects something very serious we are facing as the capacity of the HDDs is forever growing into something that could be unmanageable if the traditional implementation of RAID does not change to meet such monstrous capacity.
Yes, RAID has changed since 1988 as every vendor approaches RAID differently. NetApp was always about RAID-4 and later RAID-DP and I remembered the days when EMC had a RAID-S. There was even a vendor in the past who marketed RAID-7 but it was proprietary and wasn’t an industry standard. But fundamentally, RAID did not change in a revolutionary way and continued to withstand the ever ballooning capacities (and pressures) of the HDDs. RAID-6 was introduced when the first 1TB HDDs first came out, to address the risk of a possible second disk failure in a parity-based RAID like RAID-4 or RAID-5. But today, the 4TB HDDs could be the last straw that will break the camel’s back, or in this case, RAID’s back.
RAID-5 obviously is dead. Even RAID-6 might be considered insufficient now. Having a 3rd parity drive (3P) is an option and the only commercial technology that I know of which has 3 parity drives support is ZFS. But having 3P will cause additional overhead in performance and usable capacity. Will the fickle customer ever accept such inadequate factors?
Note that 3P is not RAID-7. RAID-7 is a trademark of a old company called Storage Computer Corporation and RAID-7 is not a standard definition of RAID.
One of the biggest concerns is rebuild times. If a 4TB HDD fails, the average rebuild speed could take days. The failure of a second HDD could up the rebuild times to a week or so … and there is vulnerability when the disks are being rebuilt.
There are a lot of talks about declustered RAID, and I think it is about time we learn about this RAID technology. At the same time, we should demand this technology before we even consider buying storage arrays with 4TB hard disk drives!
I have said this before. I am still trying to wrap my head around declustered RAID. So I invite the gurus on this matter to comment on this concept, but I am giving my understanding on the subject of declustered RAID.
Panasas‘ founder, Dr. Garth Gibson is one of the people who proposed RAID declustering way back in 1999. He is a true visionary.
One of the issues of traditional RAID today is that we still treat the hard disk component in a RAID domain as a whole device. Traditional RAID is designed to protect whole disks with block-level redundancy. An array of disks is treated as a RAID group, or protection domain, that can tolerate one or more failures and still recover a failed disk by the redundancy encoded on other drives. The RAID recovery requires reading all the surviving blocks on the other disks in the RAID group to recompute blocks lost on the failed disk. In short, the recovery, in the event of a disk failure, is on the whole object and therefore, a entire 4TB HDD has to be recovered. This is not good.
The concept of RAID declustering is to break away from the whole device idea. Apply RAID at a more granular scale. IBM GPFS works with logical tracks and RAID is applied at the logical track level. Here’s an overview of how is compares to the traditional RAID:

The logical tracks are spread out algorithmically spread out across all physical HDDs and the RAID protection layer is applied at the track level, not at the HDD device level. So, when a disk actually fails, the RAID rebuild is applied at the track level. This significant improves the rebuild times of the failed device, and does not affect the performance of the entire RAID volume much. The diagram below shows the declustered RAID’s time and performance impact when compared to a traditional RAID:

While the IBM GPFS approach to declustered RAID is applied at a semi-device level, the future is leaning towards OSD. OSD or object storage device is the next generation of storage and I blogged about it some time back. Panasas is the leader when it comes to OSD and their radical approach to this is applying RAID at the object level. They call this Object RAID.
“With object RAID, data protection occurs at the file-level. The Panasas system integrates the file system and data protection to provide novel, robust data protection for the file system. Each file is divided into chunks that are stored in different objects on different storage devices (OSD). File data is written into those container objects using a RAID algorithm to produce redundant data specific to that file. If any object is damaged for whatever reason, the system can recompute the lost object(s) using redundant information in other objects that store the rest of the file.“
The above was a quote from the blog of Brent Welch, Panasas’ Director of Software Architecture. As mentioned, the RAID protection of the objects in the OSD architecture in Panasas occurs at file-level, and the file or files constitute the object. Therefore, the recovery domain in Object RAID is at the file level, confining the risk and damage of data loss within the file level and not at the entire device level. Consequently, the speed of recovery is much, much faster, even for 4TB HDDs.
Reliability is the key objective here. Without reliability, there is no availability. Without availability, there is no performance factors to consider. Therefore, the system’s reliability is paramount when it comes to having the data protected. RAID has been the guardian all these years. It’s time to have a revolutionary approach to safeguard the reliability and ensure data availability.
So, how many vendors can claim they have declustered RAID?
Panasas is a big YES, and they apply their intelligence in large HPC (high performance computing) environments. Their technology is tried and tested. IBM GPFS is another. But where are the rest?

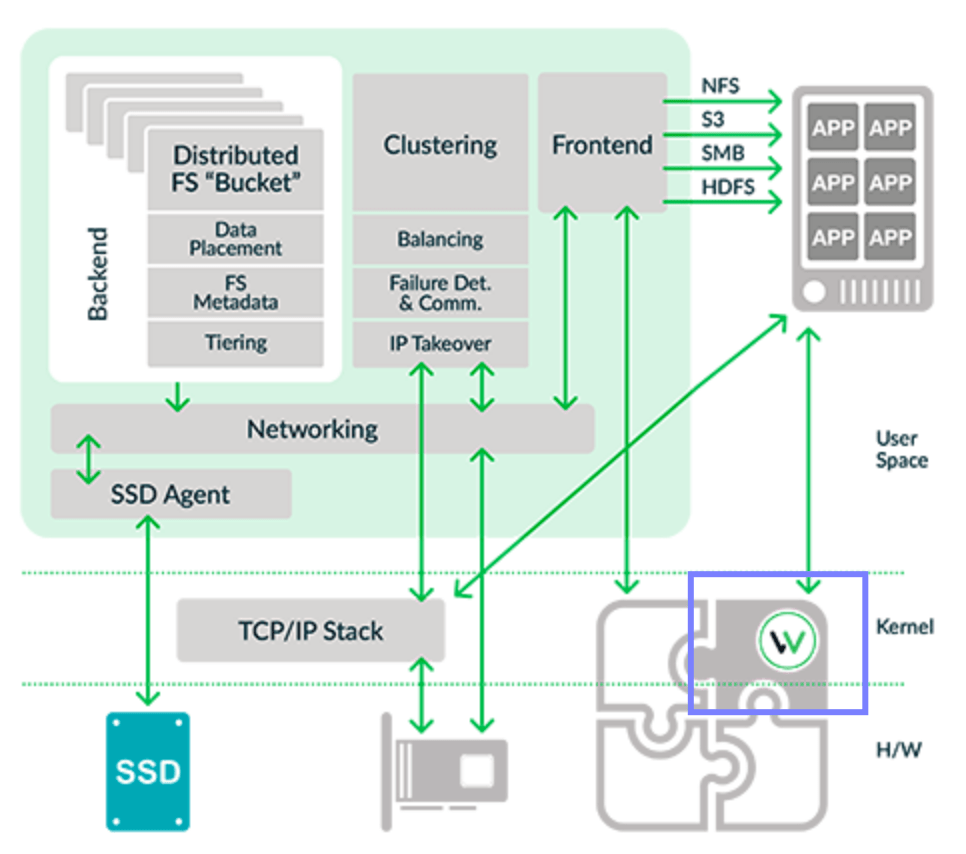 Starting from the top right corner of the diagram, applications on the Linux client (running Weka Client software) and it presents to the Linux client as a POSIX-compliant file system. Through the network, the Linux client interacts with the WekaIO kernel-based VFS (virtual file system) driver which coordinates the Front End (grey box in upper right corner) to the Linux client. Other client-based protocols such as NFS, SMB, S3 and HDFS are also supported. The Front End then interacts with the NIC (which can be 10/100G Ethernet, Infiniband, and NVMeoF) through SR-IOV (single root IO virtualization), bypassing the Linux kernel for maximum throughput. This is with WekaIO’s own networking stack in user space. Continue reading
Starting from the top right corner of the diagram, applications on the Linux client (running Weka Client software) and it presents to the Linux client as a POSIX-compliant file system. Through the network, the Linux client interacts with the WekaIO kernel-based VFS (virtual file system) driver which coordinates the Front End (grey box in upper right corner) to the Linux client. Other client-based protocols such as NFS, SMB, S3 and HDFS are also supported. The Front End then interacts with the NIC (which can be 10/100G Ethernet, Infiniband, and NVMeoF) through SR-IOV (single root IO virtualization), bypassing the Linux kernel for maximum throughput. This is with WekaIO’s own networking stack in user space. Continue reading 

