
Processing data has become more expensive.
Somewhere, there is a misconception that data processing is cheap. That stems from the well-known pricings of the capacities of public cloud storage that are a fraction of cents per month. But data in storage has to be worked upon, and has to be built up and protected to increase its value. Data has to be processed, moved, shared, and used by applications. Data induce workloads. Nobody keeps data stored forever and never be used again. Nobody buys storage just for capacity alone.
We have a great saying in the industry. No matter, where the data moves, it will land in a storage. So, it is clear that data does not exist in ether. And yet, I often see how little attention and prudence and care, when it comes to data infrastructure and data management technologies, the very components that are foundational to great data.

Great data management for Great AI
AI is driving up costs in data processing
A few recent articles drew my focus into the cost of data processing.
Here is one posted by a friend on Facebook. It is titled “The world is running out of data to feed AI, experts warn.”
My first reaction was, “How can we run out of data“? We have so much data in the world today that the 175 zettabytes predicted by IDC when we reach 2025 might be grossly inaccurate. According to Exploding Topics, it is estimated that we create 328.77TB of data per day, 120 zettabytes per year. While I cannot vouch for the accuracy of the numbers, the numbers are humongous.
Another article was posted by David Linthicum, the renowned cloud guru. He wrote “Will generative AI in the cloud become affordable?”
In both articles, we can conclude that doing AI, and whatever that are shiny now – read LLMs (large language models) and Generative AI – is going to be expensive. There are no 2 ways about it. But how do you get the best value from your data, and any data that are procured to build your organization’s AI ambitions?
Volume does not mean Value
I see many organizations constantly asking for larger and larger capacity in their storage investments over the years. It is almost always about more and more Volume. Little attention is paid when it comes to storage performance (Velocity), data relevance (Veracity), and types of data (Variety). I have even seen administrators surreptitiously running torrent services off their company’s storage, sucking up network bandwidth and storage capacity.
As you can see, I have invoked the 4Vs (Volume, Velocity, Veracity, Variety) of Big Data, but unfortunately, we can safely equate that Volume does mean Value. Most of the data, if organizations do not impose data management discipline and data hygiene, are junk.
High Quality Data
In the simplest form, put in a data management mindset. One of the greatest things I learned came from my past work at Interica (now belongs to Petrosys). In Oil and Gas subsurface data management, there is a saying “Data is the only thing for us see under the surface“. It shall be this mindset that we must procure and curate data with care, high quality data to be exact.
That is because a misstep in poor data management results in garbage data. An anecdote I recalled from the Oil & Gas industry was an incident that happened to an exploration company in Southeast Asia. They got the data wrong, and started the drilling. Each of the 4 drill initiatives ended zip. And each initiative cost a circa of USD$25 million. That was about USD$100 million going down the drain because of poor data quality.
The same thing can happen and will happen a lot with AI projects.
Objectives and key results (OKRs)
The discipline of understanding data infrastructure and data management is lacking. It is important to lay out the landscape of data within the organization. Know and inventorize the data assets. Know where they reside within the storage infrastructures, whether on-premises or in the clouds. Know how the data moves, used, where and how the data is processed. Understand the lifecycle of data, and how they can be tiered according to relevance of the business activities.
I raised this in my previous blog. Set up OKRs (objectives and key results). Know your point A, and define you point B. Align your business objectives and set your operational goals to reach the key results going from point A to point B. The outcomes is where a value of the data is derived.
The enforcement of metadata
Coming out of the shadows is metadata. The voluminous data that we create has the inherent ability to inject content-based metadata beside the usual file-based properties such as file size, owner, access times etc. The use of metadata can definitely alleviate the value of the data files and objects.
One of the useful best practices I learned during my Interica days was the Interica PARS (now incorporated into Petrosys Oneview) had the ability to enforce the G&G engineer to input their thought process during each decision gate when they are doing seismic interpretation. The engineer is forced to create not only content metadata but at the same time, capturing the knowledge and the wisdom of the G&G expert. That same mentality should be imposed in AI projects as well.
However, I find the use of metadata in AI still grossly lacking. A well droned data management discipline can create a ch0ckful of metadata that is immensely valuable in AI projects.
Data we can trust
Going back to one of the earlier mentioned articles. We are not running out of data for AI. With so much disinformation, and unworthy data, we are running out of truthful and quality data for AI. Without the truth, we cannot trust the data. We cannot trust AI.
There is an old age of Garbage in, Garbage out (GIGO) in data management. There is also an old adage that is called DIKW in data management. We can turn the Data into Information; Information into Knowledge; Knowledge into Wisdom.
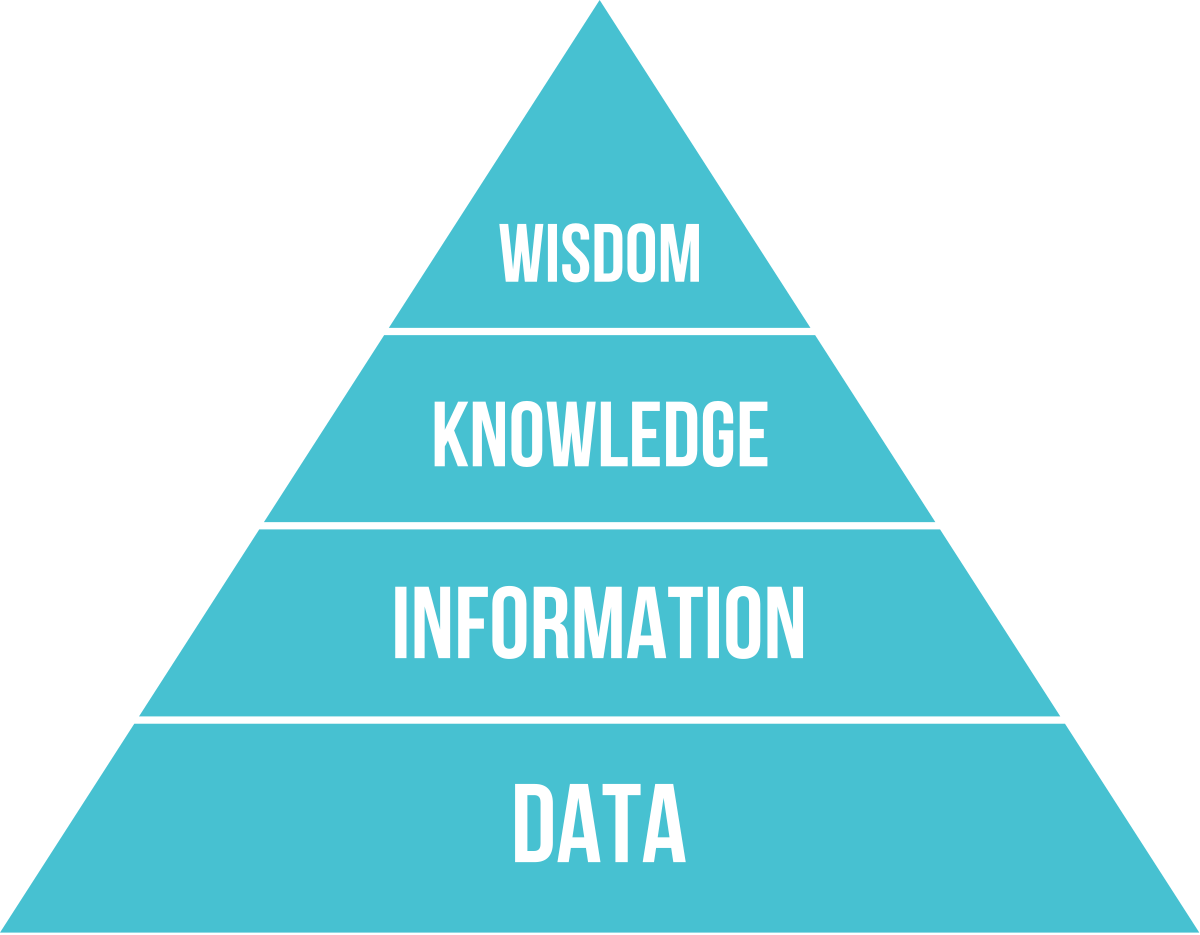
Data > Information > Knowledge > Wisdom
With that being said, organizations should not be under-investing in their data infrastructure and their data management platforms. Great value of data is created on great data foundations. We are sitting at the cusp of AI greatness. Great AI starts from good Data Management.
