The vocabulary of sources and sinks are beginning to appear in the world of data storage as we witness the new addition of data processing frameworks and the applications in this space. I wrote about this in my blog “Rethinking data. processing frameworks systems in real time” a few months ago, introducing my take on this budding new set of I/O characteristics and data ecosystem. I also started learning about the Kappa Architecture (and Lambda as well), a framework designed to craft and develop a set of amalgamated technologies to handle stream processing of a series of data in relation to time.
In Computer Science, sources and sinks are considered external entities that often serve as connectors of input and output of disparate systems. They are often not in the purview of data storage architects. Also often, these sources and sinks are viewed as black boxes, and their inner workings are hidden from the views of the data storage architects.

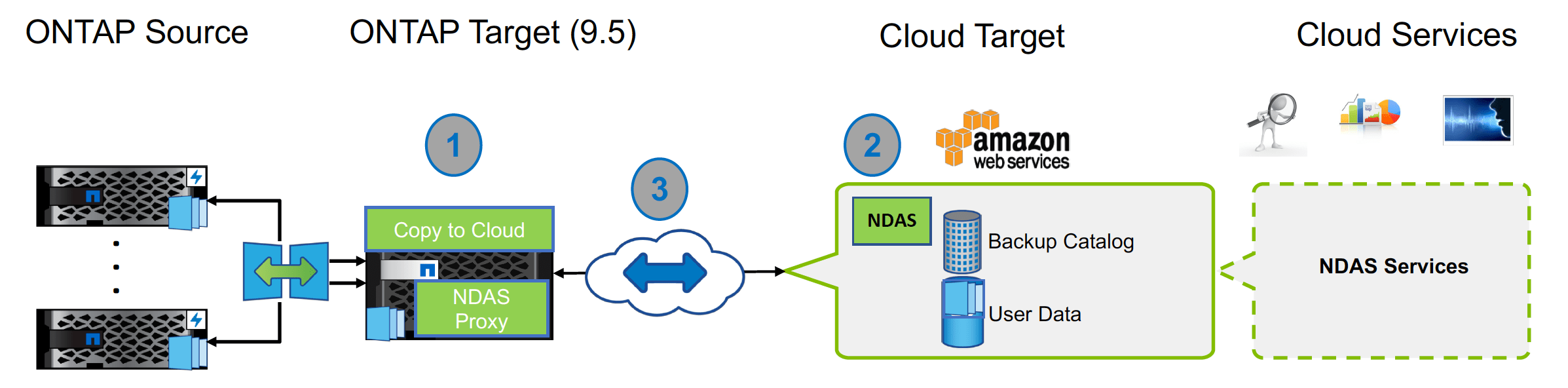
Diagram from https://developer.here.com/documentation/get-started/dev_guide/shared_content/topics/olp/concepts/pipelines.html
The changing facade of data stream processing presents the constant motion of data, the continuous data being altered as it passes through the many integrated sources and sinks. We are also see much of the data processed in-memory as much as possible. Thus, the data services from a traditional storage model of SAN and NAS may straggle with the requirements demanded by this new generation of data stream processing.
As the world of traditional data storage processing is expanding into data streams processing and vice versa, and the chatter of sources and sinks can no longer be ignored.