We get requests to recover data from a secondary platform all the time. RPO (recovery point objective) of 30 minutes can be challenging to small to medium sized companies, especially if there is an SLA (service level agreement) to meet.
This week, my team and I took some time to create a FreeNAS replication demo for a potential client. I thought I document the whole thing about ZFS replication, the key steps to set it up and show how recovery is done.
ZFS Snapshots
ZFS replication relies on periodic ZFS snapshots. ZFS snapshot is an inherent feature from the ZFS file system, and often used as a point-in-time copy of the existing ZFS file system tree in memory. Once a snapshot has been triggered, either manually or on schedule (periodic), the file system tree and its metadata in the memory are committed to disk to ensure an updated and consistent state of the file system at all times.
To start, a running snapshot policy on a schedule must be in place. This snapshot policy can be on a specific dataset or zvol, or even the entire zpool. Yeah, I am using quite a few ZFS terminology here – zpool, zvol, dataset. You can read more about each of the structures and more here.
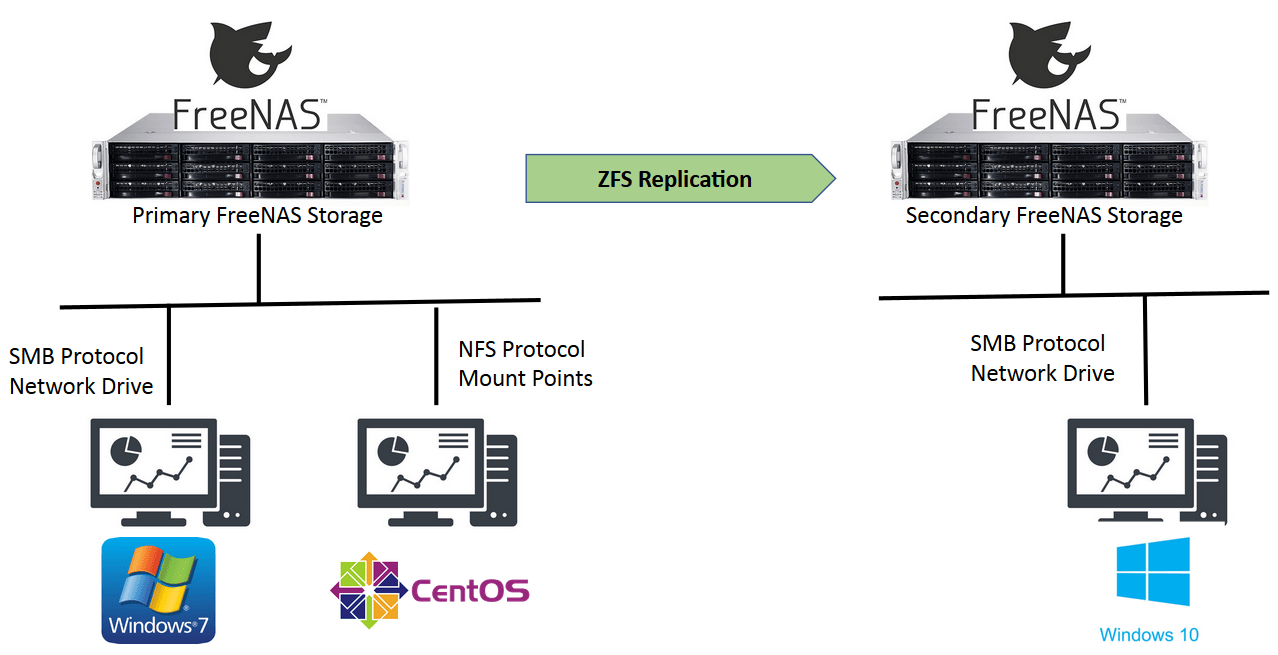
Once the ZFS replication task has been setup, every snapshot occurred in the snapshot policy is automatically duplicated and copied to the target ZFS dataset. Usually, the target ZFS dataset is on a secondary FreeNAS storage server, serving as a disaster recovery platform. Sending and receiving data in the snapshots rely on SSH service.
This is the network diagram explaining the FreeNAS ZFS replication setup.