
The IT industry uses the word “platform” all the time. Often, I find myself shifting between the many jargons circling “platform”, loosely. I am pretty sure many others are doing so as well.
I finally found the word “platformization” giving right vibes in a meaningful way in February last year, when Palo Alto Networks pivoted to platformization. Their stock tumbled that day. Despite the ambiguous definition “platformization” when Palo Alto Networks (PANW) mentioned it, I understood their strategy.
Defence-in-Depth in cybersecurity wasn’t exactly working for many organizations. Cybersecurity point solutions peppered the landscape. There were so many leaks and gaps. Platformization, from the PANW‘s point-of-view, is the reverse C&C (command & control), if you know the cybersecurity speak. PANW wants to take charge all the way for all things cybersecurity, and it made sense to me from a data perspective.
Paradigm shift for Data.
For the longest time, networked storage technology has been about data sharing, be it blocks, files or objects. The data from these protocols is delivered over the network, mostly over Fibre Channel and/or Ethernet (although I remembered implementing NFS over Asynchronous Transfer Mode at Sarawak Shell in East Malaysia), in a client-server fashion.
By late 2000s onwards, unified storage or multi-protocol storage (where the storage array is able to served all 3 SAN, NAS and S3 services) was all the rage. All the prominent enterprise storage vendors had a solution or two in their solutions portfolio. I started viewing networked storage as a Data Services Platform which I started explaining it in 2017. Within the data services platform, various features revolve around my A.P.P.A.R.M.S.C. framework (I crafted the initial framework in 2000, thanks to Jon Toigo‘s book – The Holy Grail of Data Management). This framework and the approach I used for my consulting and analyst work worked well and is still relevant, even after 25 years.
But AI is changing the data landscape. AI is changing the way data is consumed and processed through the networks between the compute layer and the storage layer. It is indeed, for me, a paradigm shift of data, and the storage layer, better known as AI Data Infrastructure now, is shifting as well. And this shift will accelerate the exponential growth in innovations, with AI and super-charged data leading the way.
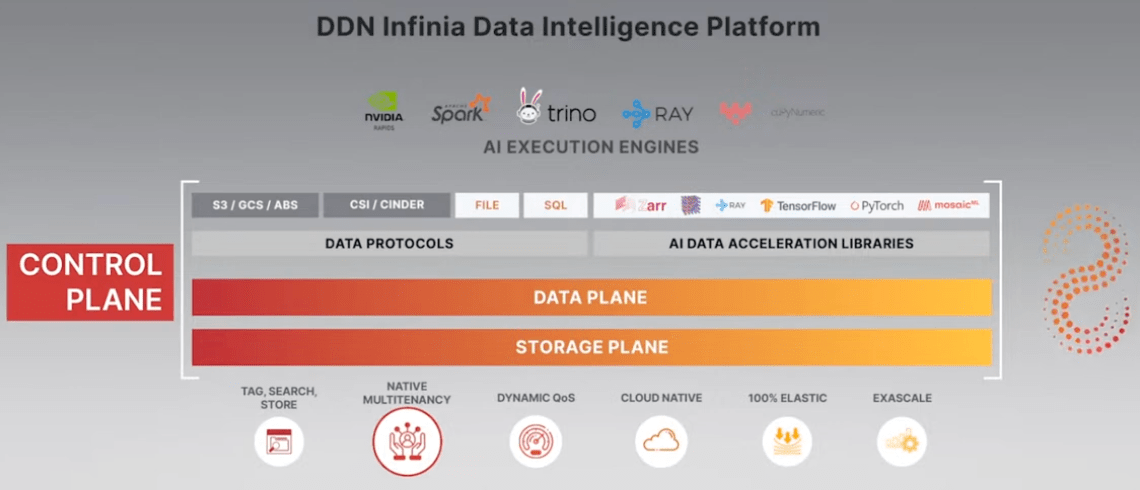
DDN Infinia Data Intelligence Platform (screencapture from DDN Beyond Artificial webinar)



