
To win in the multi-cloud game, you have to be in your competitors’ cloud. Google Cloud has been doing that since they announced Google Anthos just over a year ago. They have been crafting their “assault”, starting with on-premises, and Anthos on AWS. Anthos on Microsoft® Azure is coming, currently in preview mode.

Google CEO Sundar Pichai announcing Google Anthos at Next ’19
BigQuery Omni conversation starter
2 weeks ago, whilst the Google Cloud BigQuery Omni announcement was still under wraps, local Malaysian IT portal Enterprise IT News sent me the embargoed article to seek my views and opinions. I have to admit that I was ignorant about the deeper workings of BigQuery, and haven’t fully gone through the works of Google Anthos as well. So I researched them.
Having done some small works on Qubida (defunct) and Talend several years ago, I have grasped useful data analytics and data enablement concepts, and so BigQuery fitted into my understanding of BigQuery Omni quite well. That triggered my interests to write this blog and meshing the persistent storage conundrum (at least for me it is something to be untangled) to Kubernetes, to GKE (Google Kubernetes Engine), and thus Anthos as well.
For discussion sake, here is an overview of BigQuery Omni.
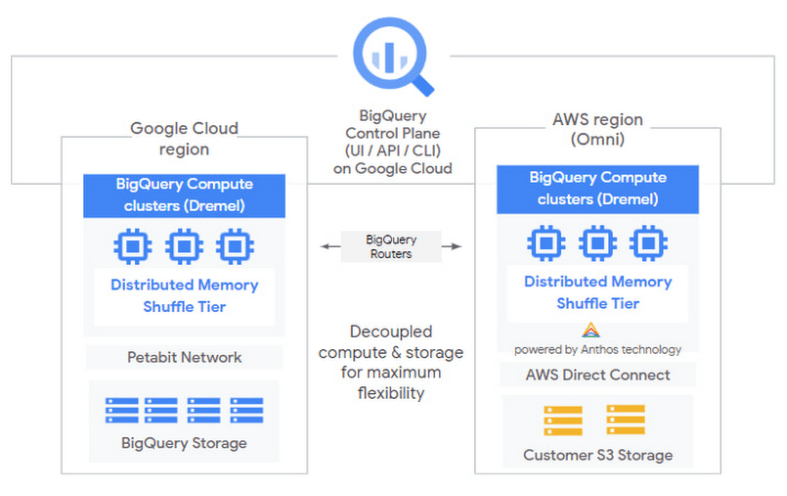
An overview of Google Cloud BigQuery Omni on multiple cloud providers
My comments and views are in this EITN article “Google Cloud’s BigQuery Omni for Multi-cloud Analytics”.



