I have been in this industry for almost 20 years. March 2, 2012 will be my 20th year, to be exact. I have never been in the mainframe era, dabbled a bit in the mini computers era during my university days and managed to ride the wave of client-server, Internet explosion in the beginning WWW days, the dot-com crash, and now Cloud Computing.
In that 20 years, I have seen the networking wars (in which TCP/IP and Cisco prevailed), the OS wars and the Balkanization of Unix (Windows NT came out the winner), the CPU wars (SPARC, PowerPC, in which x86 came out tops) and now data and storage. Yet, the last piece of the IT industry has yet to begun or has it?
In the storage wars, it was pretty much the competition between NAS and SAN and religious groups of storage in the early 2000s but now that I have been in the storage networking industry for a while, every storage vendor are beginning to look pretty much the same for me, albeit some slight differentiating factors once in a while.
In the wars that I described, there is a vendor for the product(s) that are peddled but what about memory? We never question what brand of memory we put in our servers and storage, do we? In the enterprise world, it has got to be ECC, DDR2/3 memory DIMMs and that’s about it. Why????
Even in server virtualization, the RAM and the physical or virtual memory are exactly just that – memory! Sure VMware differentiates them with a cool name called vRAM, but the logical and virtual memory is pretty much confined to what’s inside the physical server.
In clustering, architectures such as SMP and NUMA, do use shared memory. Oracle RAC shares its hosts memory for the purpose of Oracle database scalability and performance. Such aggregated memory architectures in one way or another, serves the purpose of the specific applications’ functionality rather than having the memory shared in a pool for all general applications.
What if some innovative company came along, and decided to do just that? Pool all the physical memory of all servers into a single, cohesive and integrated memory pool and every application of each of the server can use the “extended” memory in an instance, without some sort of clustering software or parallel database. One company has done it using RDMA (Remote Direct Memory Access) and their concept is shown below:

I am a big fan of RDMA ever since NetApp came out with DAFS some years ago, and I only know a little bit about RDMA because I didn’t spend a lot of time on it. But I know RDMA’s key strength in networking and when this little company called RNA Networks news came up using RDMA to create a Memory Cloud, it piqued my interest.
RNA innovated with their Memory Virtualization Acceleration (MVX) and this is layered on top of 10Gigabit Ethernet or Infiniband networks with RDMA. Within the MVX, there are 2 components of interest – RNAcache and RNAmessenger. This memory virtualization technology allows hundreds of server nodes to lend their memory into the Memory Cloud, thus creating a very large and very scalable memory pool.
As quoted:
RNA Networks then plunks a messaging engine, an API layer, and a pointer updating algorithm
on top of the global shred memory infrastructure, with the net effect that all nodes in the
cluster see the global shared memory as their own main memory.
The RNA code keeps the memory coherent across the server, giving all the benefits of an SMP
or NUMA server without actually lashing the CPUs on each machine together tightly so they
can run one copy of the operating system.
The performance gains, as claimed by RNA Networks, was enormous. In a test published, running MVX had a significant performance gain over SSDs, as shown in the results below:

This test was done in 2009/2010, so there were no comparisons with present day server-side PCIe Flash cards such as FusionIO. But even without these newer technologies, the performance gains were quite impressive.
In a previous version of 2.5, the MVX technology introduced 3 key features:
- Memory Cache
- Memory Motion
- Memory Store
The Memory Cache, as the name implied, turned the memory pool into a cache for NAS and file systems that are linked to the server. At the time, the NAS protocol supported was only NFS. The cache stored frequently accessed data sets used by the servers. Each server could have simultaneous access to the data set in the pool and MVX would be handling the contention issues.
The Memory Motion feature gives OSes and physical servers (including hypervisors) access to shared pools of memory that acts as a giant swap device during page out/swap out scenarios.
Lastly, the Memory Store was the most interesting for me. It turned the memory pool into a collection of virtual block device and was similar to the concept of RAMdisks. These RAMdisks extended very fast disks to the server nodes and the OSes, and one server node can mount multiple instances of these virtual RAMdisks. Similarly multiple server nodes can mount a single virtual RAMdisk for shared disk reasons.
The RNA Networks MVX scales hundreds of server nodes and supported architectures such as 32/64 bit x86, PowerPC, SPARC and Itanium. At the time, the MVX was available for Unix and Linux only.
The technology that RNA Networks was doing was a perfect example of how RDMA can be implemented. Before this, memory was just memory but this technology takes the last bastion of IT – the memory – out into the open. As the Cloud Computing matures, memory is going to THE component that defines the next leap forward, which is to make the Cloud work like one giant computer. Extending the memory and incorporating memory both on-premise, on the host side as well as memory in the cloud, into a fast, low latency memory pool would complete the holy grail of Cloud Computing as one giant computer.
RNA Networks was quietly acquired by Dell in July 2011 for an undisclosed sum and got absorbed into Dell Fluid Architecture’s grand scheme of things. One blog, Juku, captured an event from Dell Field Tech Day back in 2011, and it posted:
The leitmotiv here is "Fluid Data". This tagline, that originally was used by Compellent
(the term was coined by one of the earlier Italian Compellent customer), has been adopted
for all the storage lineup, bringing the fluid concept to the whole Dell storage ecosystem,
by integrating all the acquired tech in a single common platform: Ocarina will be the
dedupe engine, Exanet will be the scale-out NAS engine, RNA networks will provide an interesting
cache coherency technology to the mix while both Equallogic and Compellent have a different
targeted automatic tiering solution for traditional block storage.
Dell is definitely quietly building something and this could go on for some years. But for the author to quote – “Ocarina will be the dedupe engine, Exanet will be the scale-out NAS engine; RNA Networks will provide cache coherency technology … ” mean that Dell is determined to out-innovate some of the storage players out there.
How does it all play in Dell’s Fluid Architecture? Here’s a peek:

It will be interesting how to see how RNA Networks technology gels the Dell storage technologies together but one thing’s for sure. Memory will be the last bastion that will cement Cloud Computing into an IT foundation of the next generation.

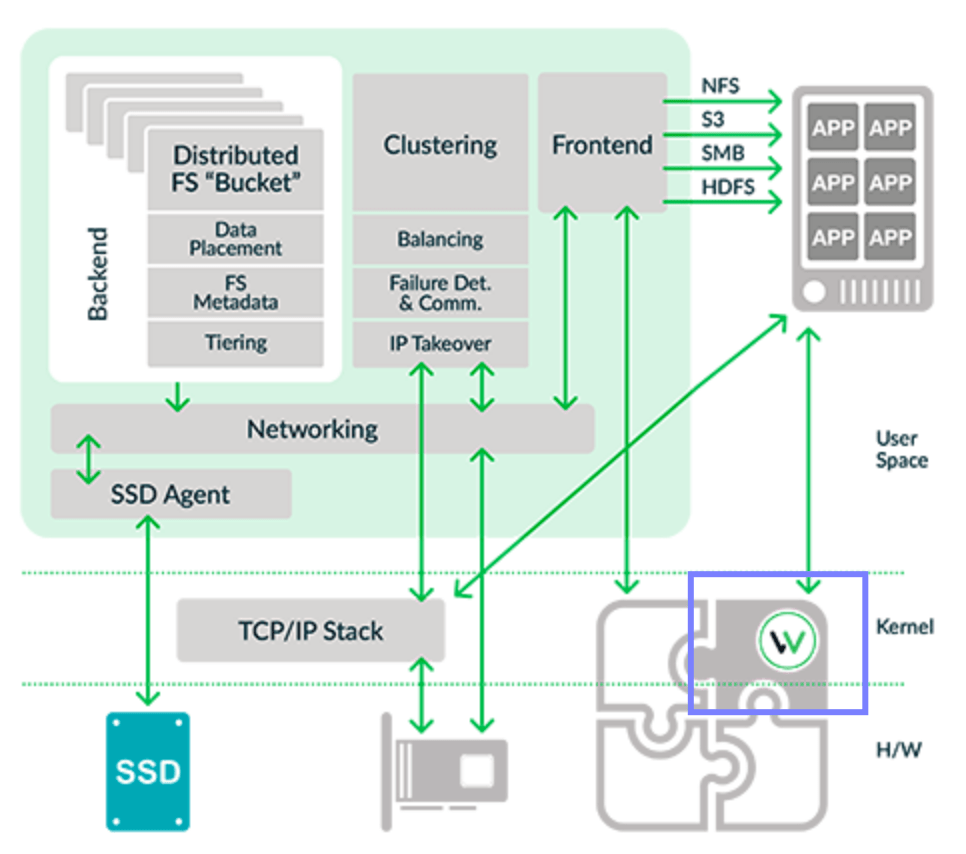 Starting from the top right corner of the diagram, applications on the Linux client (running Weka Client software) and it presents to the Linux client as a POSIX-compliant file system. Through the network, the Linux client interacts with the WekaIO kernel-based VFS (virtual file system) driver which coordinates the Front End (grey box in upper right corner) to the Linux client. Other client-based protocols such as NFS, SMB, S3 and HDFS are also supported. The Front End then interacts with the NIC (which can be 10/100G Ethernet, Infiniband, and NVMeoF) through SR-IOV (single root IO virtualization), bypassing the Linux kernel for maximum throughput. This is with WekaIO’s own networking stack in user space. Continue reading
Starting from the top right corner of the diagram, applications on the Linux client (running Weka Client software) and it presents to the Linux client as a POSIX-compliant file system. Through the network, the Linux client interacts with the WekaIO kernel-based VFS (virtual file system) driver which coordinates the Front End (grey box in upper right corner) to the Linux client. Other client-based protocols such as NFS, SMB, S3 and HDFS are also supported. The Front End then interacts with the NIC (which can be 10/100G Ethernet, Infiniband, and NVMeoF) through SR-IOV (single root IO virtualization), bypassing the Linux kernel for maximum throughput. This is with WekaIO’s own networking stack in user space. Continue reading 




