[Disclosure: I was invited by Dell Technologies as a delegate to their Dell Technologies World 2019 Conference from Apr 29-May 1, 2019 in the Las Vegas USA. Tech Field Day Extra was an included activity as part of the Dell Technologies World. My expenses, travel, accommodation and conference fees were covered by Dell Technologies, the organizer and I was not obligated to blog or promote their technologies presented at this event. The content of this blog is of my own opinions and views]
Deep Learning, Neural Networks, Machine Learning and subsequently Artificial Intelligence (AI) are the new generation of applications and workloads to the commercial HPC systems. Different from the traditional, more scientific and engineering HPC workloads, I have written about the new dawn of supercomputing and the attractive posture of commercial HPC.
Don’t be idle
From the business perspective, the investment of HPC systems is high most of the time, and justifying it to the executives and the investors is not easy. Therefore, it is critical to keep feeding the HPC systems and significantly minimize the idle times for compute, GPUs, network and storage.
However, almost all HPC systems today are inflexible. Once assigned to a project, the resources pretty much stay with the project, even when the workload processing of the project is idle and waiting. Of course, we have to bear in mind that not all resources are fully abstracted, virtualized and software-defined whereby you can carve out pieces of the hardware and deliver a percentage of that resource. Case in point is the CPU, where you cannot assign certain clock cycles of CPU to one project and another half to the other. The technology isn’t there yet. Certain resources like GPU is going down the path of Virtual GPU, and into the realm of resource disaggregation. Eventually, all resources of the HPC systems – CPU, memory, FPGA, GPU, PCIe channels, NVMe paths, IOPS, bandwidth, burst buffers etc – should be disaggregated and pooled for disparate applications and workloads based on demands of usage, time and performance.
Hence we are beginning to see the disaggregated HPC systems resources composed and built up the meet the diverse mix and needs of HPC applications and workloads. This is even more acute when a AI project might grow cold, but the training of AL/ML/DL workloads continues to stay hot
Liqid the early leader in Composable Architecture
 Continue reading →
Continue reading →

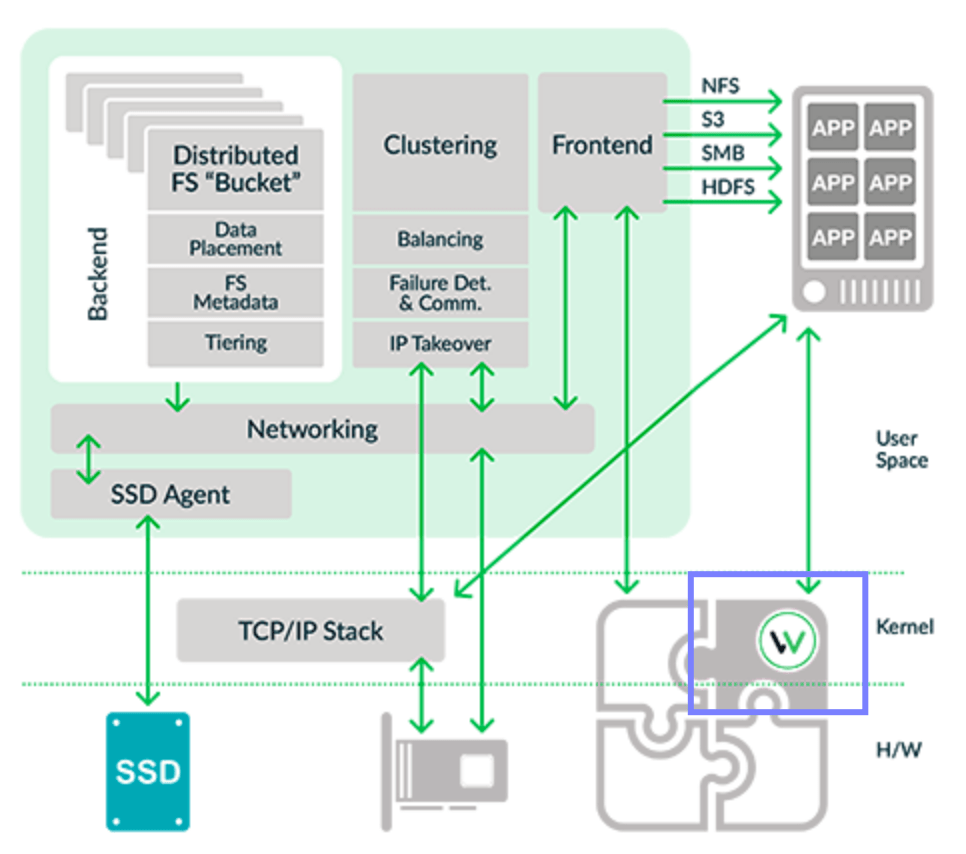
 Cray, SGI and WekaIO are all strong HPC technology companies. Given the strong uptick in the HPC market, especially commercial HPC, we cannot deny HPE’s ambition to become the top SuperComputing and HPC vendor in the industry. Continue reading
Cray, SGI and WekaIO are all strong HPC technology companies. Given the strong uptick in the HPC market, especially commercial HPC, we cannot deny HPE’s ambition to become the top SuperComputing and HPC vendor in the industry. Continue reading