[Disclosure: I was invited by GestaltIT as a delegate to their Storage Field Day 19 event from Jan 22-24, 2020 in the Silicon Valley USA. My expenses, travel, accommodation and conference fees were covered by GestaltIT, the organizer and I was not obligated to blog or promote the vendors’ technologies to be presented at this event. The content of this blog is of my own opinions and views]
Western Digital dived into Storage Field Day 19 in full force as they did in Storage Field Day 18. A series of high impact presentations, each curated for the diverse requirements of the audience. Several open source initiatives were shared, all open standards to address present inefficiencies and designed and developed for a greater future.
Zoned Storage
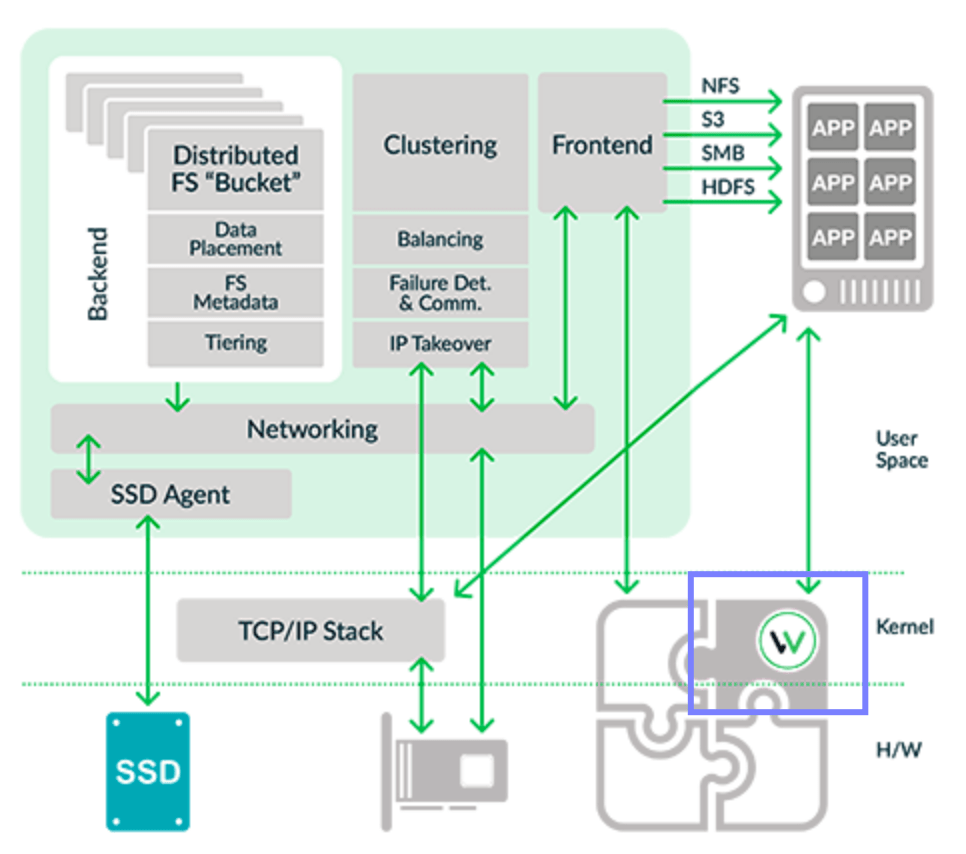
One of the initiatives is to increase the efficiencies around SMR and SSD zoning capabilities and removing the complexities and overlaps of both mediums. This is the Zoned Storage initiatives a technical working proposal to the existing NVMe standards. The resulting outcome will give applications in the user space more control on the placement of data blocks on zone aware devices and zoned SSDs, collectively as Zoned Block Device (ZBD). The implementation in the Linux user and kernel space is shown below: