[ Note: This article was published on LinkedIn on Jan 20th 2020. Here is the link to the original article ]
Digital Transformation is again a big word for 2020. As more and more organizations becoming digitalized, the opportunity to communicate, interact and collaborate has become easier, faster, more convenient than ever.
File Sharing forever
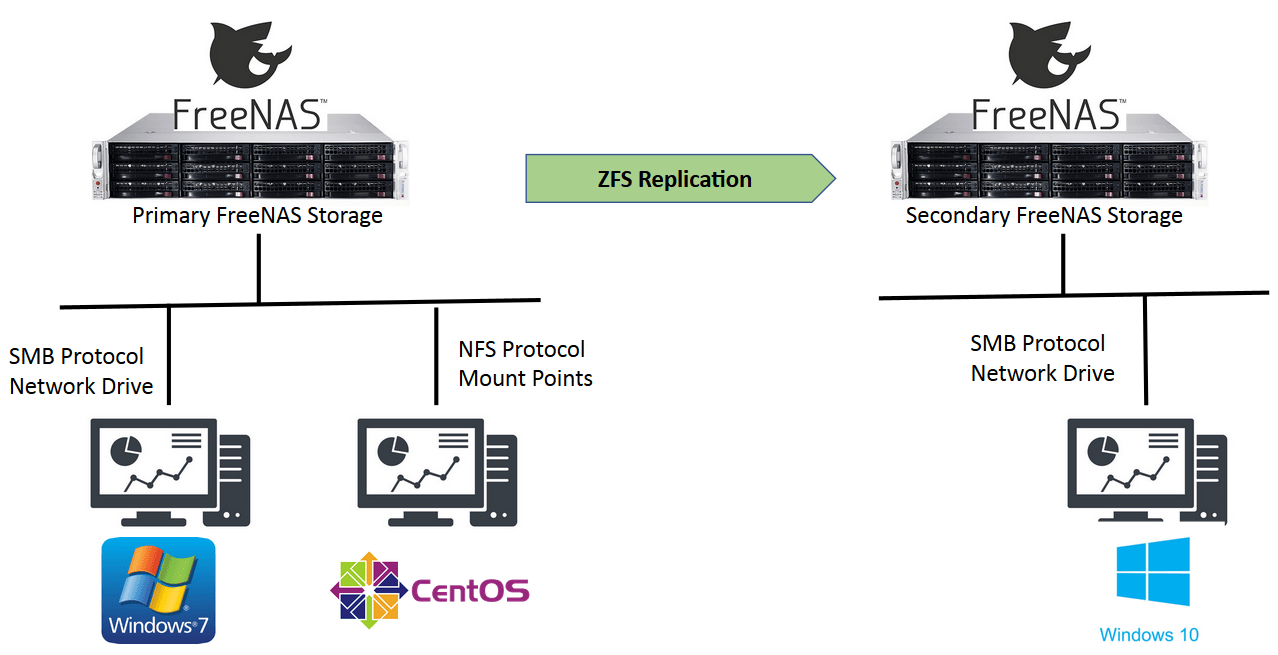
Working in projects, file sharing is a fundamental activity that underpins communication and collaboration. Network drives via NAS (network attached storage) for file sharing are common within the confines of the company network. The perimeter of the company’s network is further extended via VPN (virtual private network) access, allowing branch offices and remote individuals to access the files from the central NAS server. It is a workable solution albeit poor network performance in delivery, challenges of siloed data management and difficult scalability.
The phenomenon of Dropbox
When Dropbox arrived circa 2008-2009, it took the industry by storm. They practically invented the term BYOD (bring your own device) and capture the imagination of the file sharing market. Gartner recognized this and coined EFSS (enterprise file sync and share) to consolidate the burgeoning file sharing market. Pretenders and challengers flooded the market, and after the shakedown, Box.net, Microsoft OneDrive, Google Drive and of course, Dropbox, are some of the market leaders today.
A recent report by Markets & Markets listed these companies as players in the EFSS market.

As the wheels of Digital Transformation turn, EFSS is changing as well. Gartner EFSS is now the CCP (content collaboration platform), releasing their Gartner Content Collaboration Platforms MarketPeer Insights report in April 2019. Continue reading