[Preamble: I have been invited by GestaltIT as a delegate to their Tech Field Day for Storage Field Day 18 from Feb 27-Mar 1, 2019 in the Silicon Valley USA. My expenses, travel and accommodation were covered by GestaltIT, the organizer and I was not obligated to blog or promote their technologies presented at this event. The content of this blog is of my own opinions and views]
I was first introduced to WekaIO back in Storage Field Day 15. I did not blog about them back then, but I have followed their progress quite attentively throughout 2018. 2 Storage Field Days and a year later, they were back for Storage Field Day 18 with a new CTO, Andy Watson, and several performance benchmark records.
Blowout year
2018 was a blowout year for WekaIO. They have experienced over 400% growth, placed #1 in the Virtual Institute IO-500 10-node performance challenge, and also became #1 in the SPEC SFS 2014 performance and latency benchmark. (Note: This record was broken by NetApp a few days later but at a higher cost per client)
The Virtual Institute for I/O IO-500 10-node performance challenge was particularly interesting, because it pitted WekaIO against Oak Ridge National Lab (ORNL) Summit supercomputer, and WekaIO won. Details of the challenge were listed in Blocks and Files and WekaIO Matrix Filesystem became the fastest parallel file system in the world to date.
Control, control and control
I studied WekaIO’s architecture prior to this Field Day. And I spent quite a bit of time digesting and understanding their data paths, I/O paths and control paths, in particular, the diagram below:
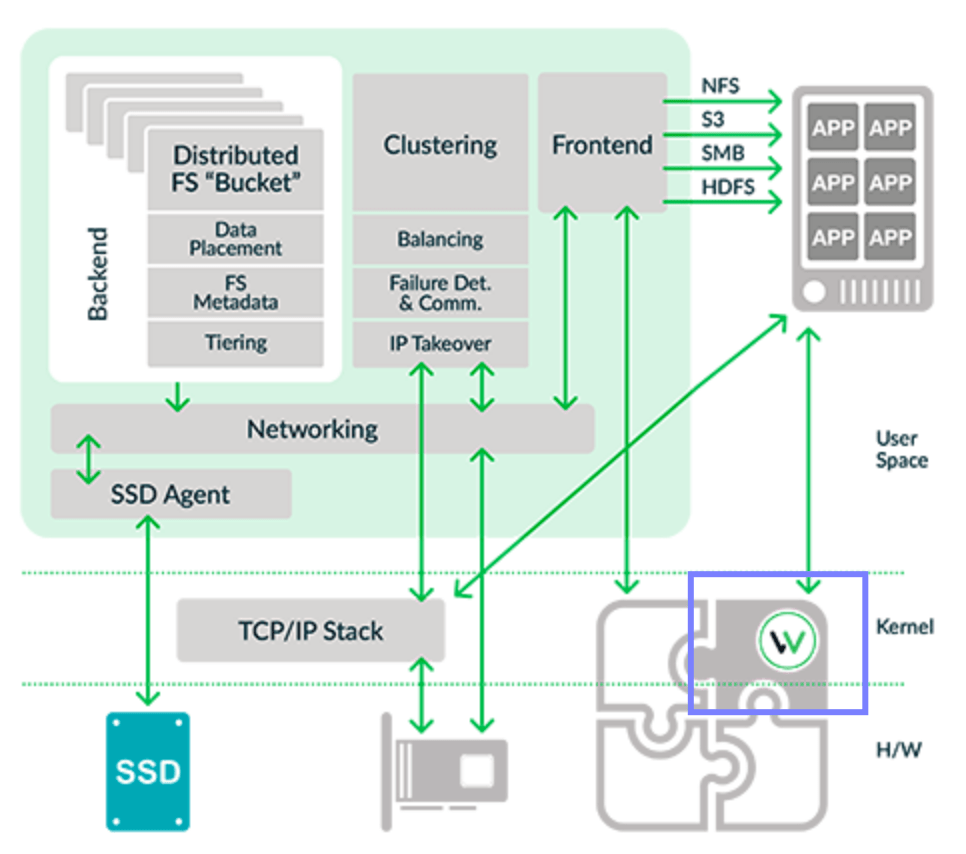 Starting from the top right corner of the diagram, applications on the Linux client (running Weka Client software) and it presents to the Linux client as a POSIX-compliant file system. Through the network, the Linux client interacts with the WekaIO kernel-based VFS (virtual file system) driver which coordinates the Front End (grey box in upper right corner) to the Linux client. Other client-based protocols such as NFS, SMB, S3 and HDFS are also supported. The Front End then interacts with the NIC (which can be 10/100G Ethernet, Infiniband, and NVMeoF) through SR-IOV (single root IO virtualization), bypassing the Linux kernel for maximum throughput. This is with WekaIO’s own networking stack in user space. Continue reading
Starting from the top right corner of the diagram, applications on the Linux client (running Weka Client software) and it presents to the Linux client as a POSIX-compliant file system. Through the network, the Linux client interacts with the WekaIO kernel-based VFS (virtual file system) driver which coordinates the Front End (grey box in upper right corner) to the Linux client. Other client-based protocols such as NFS, SMB, S3 and HDFS are also supported. The Front End then interacts with the NIC (which can be 10/100G Ethernet, Infiniband, and NVMeoF) through SR-IOV (single root IO virtualization), bypassing the Linux kernel for maximum throughput. This is with WekaIO’s own networking stack in user space. Continue reading