[Preamble: I have been invited by GestaltIT as a delegate to their Tech Field Day for Storage Field Day 18 from Feb 27-Mar 1, 2019 in the Silicon Valley USA. My expenses, travel and accommodation were covered by GestaltIT, the organizer and I was not obligated to blog or promote their technologies presented at this event. The content of this blog is of my own opinions and views]
The NetApp Data Fabric Vision
The NetApp Data Fabric vision has always been clear to me. Maybe it was because of my 2 stints with them, and I got well soaked in their culture. 3 simple points define the vision.
- The Data Fabric is THE data singularity. Data can be anywhere – on-premises, the clouds, and more.
- Have bridges, paths and workflows management to the Data, to move the data to wherever the data may be.
- Work with technology partners to build tools and data systems to elevate the value of the data
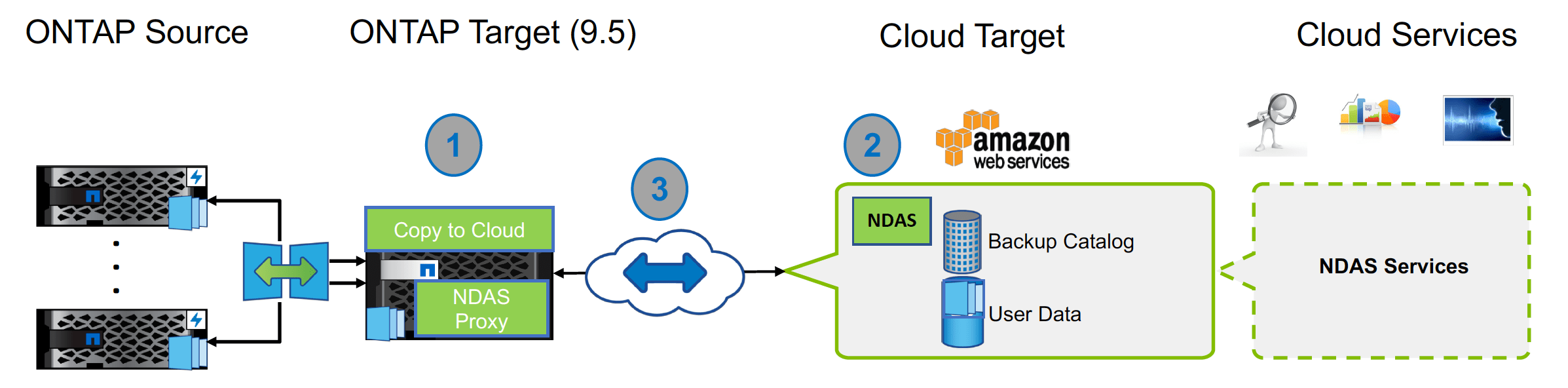
That is how I see it. I wrote about the Transcendence of the Data Fabric vision 3+ years ago, and I emphasized the importance of the Data Pipeline in another NetApp blog almost a year ago. The introduction of NetApp Data Availability Services (NDAS) in the recently concluded Storage Field Day 18 was no different as NetApp constructs data bridges and paths to the AWS Cloud.
NetApp Data Availability Services
The NDAS feature is only available with ONTAP 9.5. With less than 5 clicks, data from ONTAP primary systems can be backed up to the secondary ONTAP target (running the NDAS proxy and the Copy to Cloud API), and then to AWS S3 buckets in the cloud.